In this blog, we discuss how to improve the inference latencies of the Llama 2 family of models using PyTorch native optimizations such as native fast kernels, compile transformations from torch compile, and tensor parallel for distributed inference. Our approach results in 29ms/token latency for single user requests on the 70B LLaMa model (as measured on 8 A100 GPUs). We are excited to share our findings with the community and make our code available here.
Background
We are amid a generative AI revolution with large language models of tens of billions of parameters becoming commoditized and available for use. However, it is well recognized in the community that deploying these large models in a cost-efficient manner remains a key challenge. Many different approaches have been attempted with varying degrees of success and offering different trade-offs. Hardware-specific optimizations (e.g., Faster Transformer from NVIDIA) are restricted to specific target hardware whereas approaches that rely on layers of abstraction (e.g., ONNX) enable arbitrary models but suffer from loss of efficiency. With the introduction of PyTorch compile last year, IBM and the PyTorch team started exploring the use of model compilation for inference optimizations with the goal of reducing the latency per token for generative models.
Model Choice
We choose to benchmark on the Llama 2 family of models, given their popularity. The models that we are interested in, and their hyper parameters relevant for this blog are given in the below table:
| Model size | Hidden dimension | Num heads | Num layers | Attention type |
| 7B | 4096 | 32 | 32 | MHA |
| 13B | 5120 | 40 | 40 | MHA |
| 70B | 8192 | 64 | 80 | GQA |
These models are decoder only, which means that tokens get generated in a serialized manner, which is typically sped up using KV caching. We take a similar approach in our latency and throughput measurements.
Inference Approach
Our goal for inference is to provide a path for achieving the best possible latencies rapidly, to keep up with the velocity with which new model architectures are emerging in the community. A PyTorch native approach is appealing as it allows for the maximum flexibility in terms of “coverage” of models. We note that there are four orthogonal techniques that provide acceleration in inference: (a) Kernel fusion using compile, (b) Faster kernels, (c) Tensor parallel for larger models, and (d) Quantization. In our approach, we use the first three of these four levers - compile natively working with faster kernels from SDPA and a custom tensor parallel implementation that all work hand-in-glove to achieve inference latencies of 29ms/token on a 70B model as measured on 8 NVIDIA A100 GPUs with single user.
Compile all the way!
PyTorch Compile leverages tracing and graph capture to reduce the CPU overhead and in an ideal scenario results in a single graph execution/instruction from CPU to GPU. However, often compile introduces graph breaks due to model architecture and ops unsupported by compile. For example, complex operations such as einops are not supported by compile today. Similarly, tensor parallel inference can introduce graph breaks at each layer, since compile requires the tensor parallel implementation to use traceable communication collectives. If these graph breaks are not removed, the performance of the compiled artifacts will be hampered and could even be lower compared to eager mode execution. To get full benefit of the compiled artifacts, the graph breaks need to be removed.
Below, we describe how we went about doing this for the 70b Llama 2 model and the challenges we had to overcome to get compile to work all the way through.
Our first attempt was to try using torch.compile to compile the out-of-box Llama 2 model, but it failed because complex ops were not supported. Using TORCH_COMPILE_DEBUG = 1 we identified the RoPE positional encodings was using complex number functions resulting in graph breaks and significant slowdowns. We rewrote the RoPE function to bypass torch.einsum (Original implementation uses torch.polar that also conflicts with compile) and use torch.cos and torch.sin instead.
self.cached_freqs[dev_idx][alpha] = torch.stack(
[
torch.cos(freqs),
-torch.sin(freqs),
torch.sin(freqs),
torch.cos(freqs),
],
dim=2,
).view(*freqs.shape, 2, 2)
Our implementation of the frequencies computation
t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
t = t / self.scaling_factor
freqs = torch.einsum("i,j->ij", t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1)
self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(dtype), persistent=False)
self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(dtype), persistent=False)
Hugging Face implementation of the frequencies computation
Once RoPE was fixed, we were able to get 7B and 13B models to compile without ANY graph breaks on a single A100 GPU.
We used SDPA, the PyTorch native implementation of efficient attention computation with tracing enabled (for compile). To avoid graph breaks related to forcing a single algorithm choice using a Python context, the recommended way, we had to use the torch.backends.cuda.enable_*_sdp functions.
attn = torch.nn.functional.scaled_dot_product_attention(
queries,
keys_e,
values_e,
attn_mask=attn_mask,
dropout_p=self.p_dropout if self.training else 0.0,
is_causal=is_causal_mask,
)
Attention computation using SDPA
Next we ran the same steps for the larger 70B model and found that even with half precision, the model does not fit in a single GPU and requires tensor parallel inference. Using torch.compile for the 70B model resulted in 162 graph breaks due to two all-reduces per layer, one all-gather for forward embedding, and one all-gather for reverse embedding. Due to this, we saw no significant improvement in inference latencies. We could not use the distributed tensor implementation from PyTorch at the time of writing this blog as it did not support compile. We rewrote the tensor parallel code from scratch so that it only depends on traceable collectives to make it work with compile. After this last change, PyTorch compiler did not introduce any graph breaks and we saw a significant speedup in inference latencies. Specifically, we measured latencies for the Llama 70B model at 29ms/token when using 8 A100 GPUs, a 2.4x improvement over unoptimized inference.
Serving aspects
Finally, a point to note here is that simply performing compile on a model is not sufficient to serve the model in a production setting. To realize the above performance with high throughput, we need to support dynamic batching, nested tensors, as well as have a warm up phase where we pre-compile for bucketized sequence lengths. We are working on these aspects to realize such performance in a production setting.
Experiments and Measurements
We use nodes with 8 A100 NVIDIA GPUs with 80G cards for all our measurements in two different environments (IBM Cloud and AWS, both running OpenShift). First, we compare the various techniques – eager mode, with SDPA Flash kernel, with Compile, and with Compile and SDPA. For the 70B model, we run it in Tensor Parallel mode with compile and SDPA. For this experiment, we use 512 tokens as input length with 50 token generation. For 7 and 13B models, we use single A100 for measurement of latencies, whereas we use 8 A100s for the 70B model. In addition, for the 70B model we use the reduce-overhead option in PyTorch compile that uses CudaGraphs to reduce CPU to GPU kernel launching overheads; the use of CudaGraphs in the 7B and 13B models did not show any benefits (and are thus not reported here). We observe from Figure 1 that compile and SDPA provide very low latencies, with 70B Llama 2 model at 29ms/token.
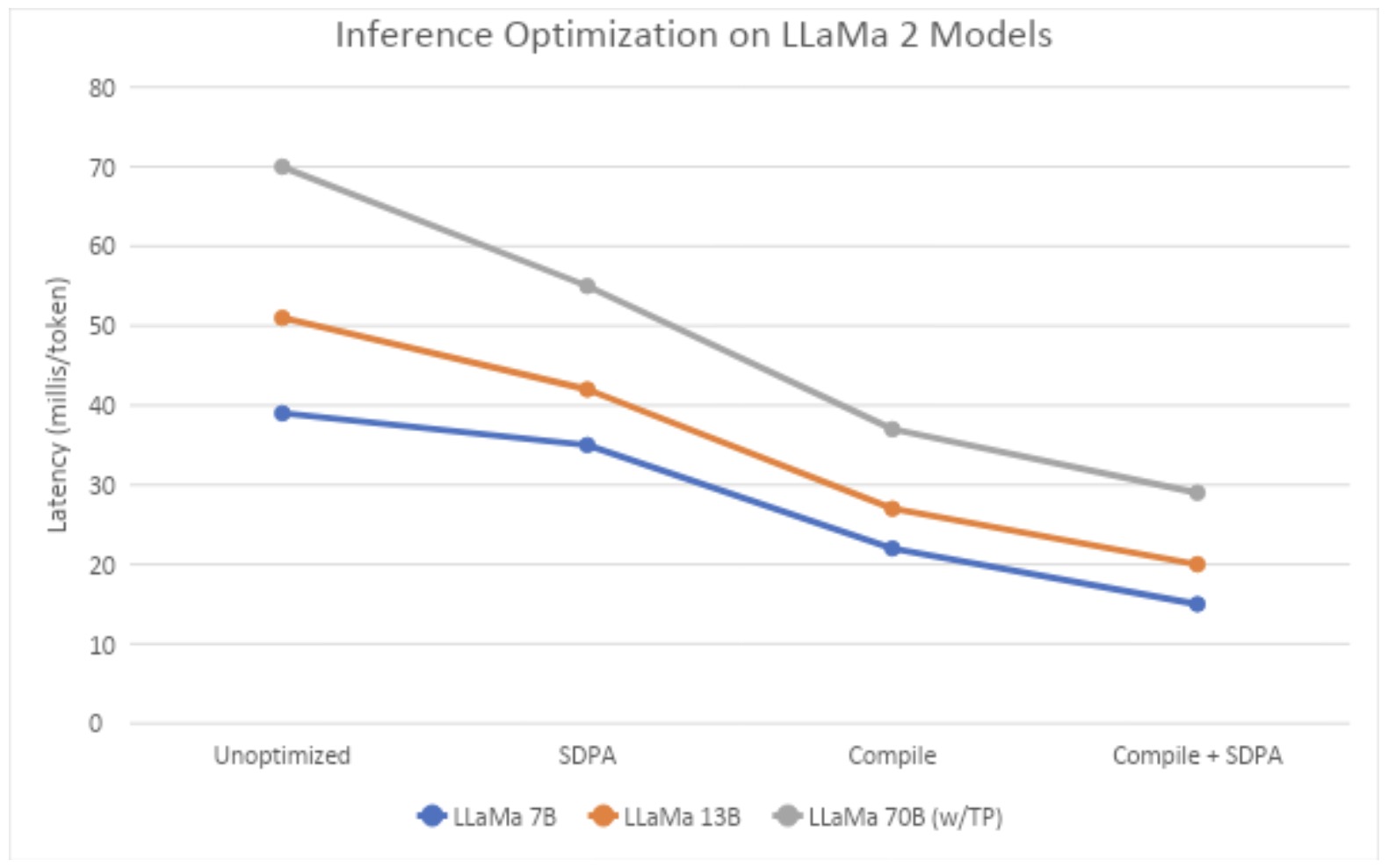
Fig. 1: Median latency across different techniques with sequence length 512 (measured on IBM Cloud A100 servers)
Next, we examine the impact of sequence length, where we increase it from 1024 to 4096 and observe that the median latency per token increases sub-linearly, demonstrating that when we increase context to large documents, we do not sacrifice response times.
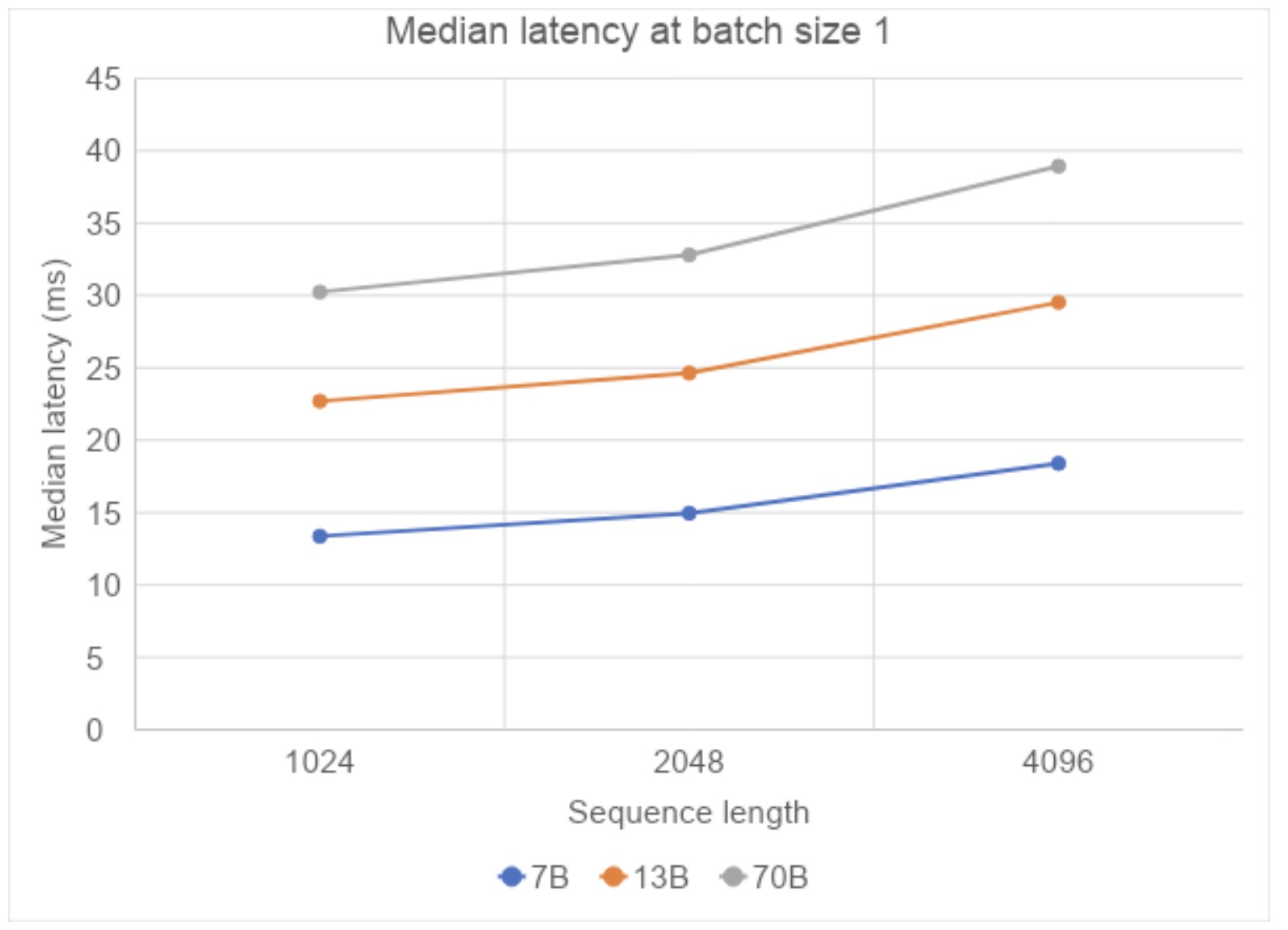
Fig. 2: Median latency for compile+SDPA with different sequence lengths (Measured on A100s on AWS)
Finally, with increased batch sizes, we observe that the response latencies increase sub-linearly. For the 13B model, at batch size 8, we encounter an OOM. For the 70B model, given that it is running on 8 GPUs with tensor parallel, we do not see any such OOM issues.
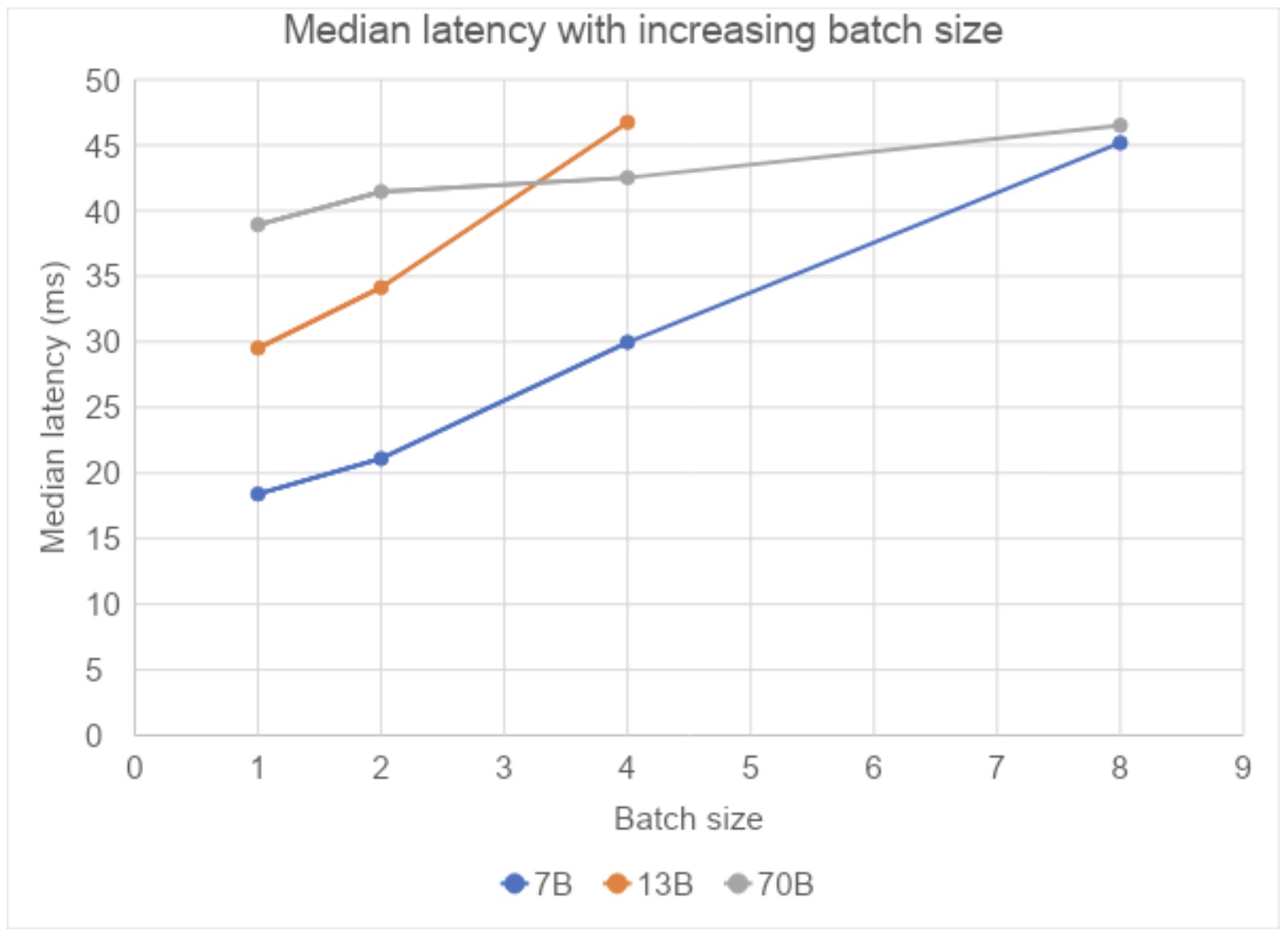
Fig. 3: Median latency for compile+SDPA with different batch sizes and sequence length fixed at 4096 (Measured on A100s on AWS)
Final Thoughts
We have demonstrated how a PyTorch compile pathway for inference demonstrates ultra low latencies for 70B model inference. The next steps are to enable dynamic batching and nested tensors with the above levers.
Special thanks to Edward Yang, Elias Ellison, Driss Guessous, Will Feng, Will Constable, Horace He, Less Wright, and Andrew Gu from Team PyTorch, whose PRs reviews and code contributions made it possible for us to realize the latencies using PyTorch native approach. We thank the broader Team PyTorch that have been tirelessly working to make PyTorch better, special shout outs to the SDPA team for enabling tracing and compile on fast kernels, the compile team that has been closely guiding us on how to work around as well as fix issues (including identifying and raising NVIDIA driver bugs in CUDA graphs).
Inference latency has been one of the roadblocks for LLM adoption in critical enterprise workflows, but another major one is the need for safety, trustworthiness and governance. IBM’s guide for AI safety and LLM risk can be found here and Meta’s responsible user guide for LLaMa can be found here.
References
- GitHub resources: https://ibm.biz/fm-stack
- The Path to Achieve Ultra-Low Inference Latency With LLaMa 65B on PyTorch/XLA
- Speed, Python: Pick Two. How CUDA Graphs Enable Fast Python Code for Deep Learning
- IBM’s resources on AI Ethics and Trust: https://www.ibm.com/downloads/cas/E5KE5KRZ
- Meta LLaMa responsible user guide: https://ai.meta.com/llama/responsible-use-guide/
