TorchVision has a new backwards compatible API for building models with multi-weight support. The new API allows loading different pre-trained weights on the same model variant, keeps track of vital meta-data such as the classification labels and includes the preprocessing transforms necessary for using the models. In this blog post, we plan to review the prototype API, show-case its features and highlight key differences with the existing one.

We are hoping to get your thoughts about the API prior finalizing it. To collect your feedback, we have created a Github issue where you can post your thoughts, questions and comments.
Limitations of the current API
TorchVision currently provides pre-trained models which could be a starting point for transfer learning or used as-is in Computer Vision applications. The typical way to instantiate a pre-trained model and make a prediction is:
import torch
from PIL import Image
from torchvision import models as M
from torchvision.transforms import transforms as T
img = Image.open("test/assets/encode_jpeg/grace_hopper_517x606.jpg")
# Step 1: Initialize model
model = M.resnet50(pretrained=True)
model.eval()
# Step 2: Define and initialize the inference transforms
preprocess = T.Compose([
T.Resize([256, ]),
T.CenterCrop(224),
T.PILToTensor(),
T.ConvertImageDtype(torch.float),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# Step 3: Apply inference preprocessing transforms
batch = preprocess(img).unsqueeze(0)
prediction = model(batch).squeeze(0).softmax(0)
# Step 4: Use the model and print the predicted category
class_id = prediction.argmax().item()
score = prediction[class_id].item()
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
category_name = categories[class_id]
print(f"{category_name}: {100 * score}%")
There are a few limitations with the above approach:
- Inability to support multiple pre-trained weights: Since the
pretrainedvariable is boolean, we can only offer one set of weights. This poses a severe limitation when we significantly improve the accuracy of existing models and we want to make those improvements available to the community. It also stops us from offering pre-trained weights of the same model variant on different datasets. - Missing inference/preprocessing transforms: The user is forced to define the necessary transforms prior using the model. The inference transforms are usually linked to the training process and dataset used to estimate the weights. Any minor discrepancies in these transforms (such as interpolation value, resize/crop sizes etc) can lead to major reductions in accuracy or unusable models.
- Lack of meta-data: Critical pieces of information in relation to the weights are unavailable to the users. For example, one needs to look into external sources and the documentation to find things like the category labels, the training recipe, the accuracy metrics etc.
The new API addresses the above limitations and reduces the amount of boilerplate code needed for standard tasks.
Overview of the prototype API
Let’s see how we can achieve exactly the same results as above using the new API:
from PIL import Image
from torchvision.prototype import models as PM
img = Image.open("test/assets/encode_jpeg/grace_hopper_517x606.jpg")
# Step 1: Initialize model
weights = PM.ResNet50_Weights.IMAGENET1K_V1
model = PM.resnet50(weights=weights)
model.eval()
# Step 2: Initialize the inference transforms
preprocess = weights.transforms()
# Step 3: Apply inference preprocessing transforms
batch = preprocess(img).unsqueeze(0)
prediction = model(batch).squeeze(0).softmax(0)
# Step 4: Use the model and print the predicted category
class_id = prediction.argmax().item()
score = prediction[class_id].item()
category_name = weights.meta["categories"][class_id]
print(f"{category_name}: {100 * score}*%*")
As we can see the new API eliminates the aforementioned limitations. Let’s explore the new features in detail.
Multi-weight support
At the heart of the new API, we have the ability to define multiple different weights for the same model variant. Each model building method (eg resnet50) has an associated Enum class (eg ResNet50_Weights) which has as many entries as the number of pre-trained weights available. Additionally, each Enum class has a DEFAULT alias which points to the best available weights for the specific model. This allows the users who want to always use the best available weights to do so without modifying their code.
Here is an example of initializing models with different weights:
from torchvision.prototype.models import resnet50, ResNet50_Weights
# Legacy weights with accuracy 76.130%
model = resnet50(weights=ResNet50_Weights.IMAGENET1K_V1)
# New weights with accuracy 80.858%
model = resnet50(weights=ResNet50_Weights.IMAGENET1K_V2)
# Best available weights (currently alias for IMAGENET1K_V2)
model = resnet50(weights=ResNet50_Weights.DEFAULT)
# No weights - random initialization
model = resnet50(weights=None)
Associated meta-data & preprocessing transforms
The weights of each model are associated with meta-data. The type of information we store depends on the task of the model (Classification, Detection, Segmentation etc). Typical information includes a link to the training recipe, the interpolation mode, information such as the categories and validation metrics. These values are programmatically accessible via the meta attribute:
from torchvision.prototype.models import ResNet50_Weights
# Accessing a single record
size = ResNet50_Weights.IMAGENET1K_V2.meta["size"]
# Iterating the items of the meta-data dictionary
for k, v in ResNet50_Weights.IMAGENET1K_V2.meta.items():
print(k, v)
Additionally, each weights entry is associated with the necessary preprocessing transforms. All current preprocessing transforms are JIT-scriptable and can be accessed via the transforms attribute. Prior using them with the data, the transforms need to be initialized/constructed. This lazy initialization scheme is done to ensure the solution is memory efficient. The input of the transforms can be either a PIL.Image or a Tensor read using torchvision.io.
from torchvision.prototype.models import ResNet50_Weights
# Initializing preprocessing at standard 224x224 resolution
preprocess = ResNet50_Weights.IMAGENET1K_V2.transforms()
# Initializing preprocessing at 400x400 resolution
preprocess = ResNet50_Weights.IMAGENET1K_V2.transforms(crop_size=400, resize_size=400)
# Once initialized the callable can accept the image data:
# img_preprocessed = preprocess(img)
Associating the weights with their meta-data and preprocessing will boost transparency, improve reproducibility and make it easier to document how a set of weights was produced.
Get weights by name
The ability to link directly the weights with their properties (meta data, preprocessing callables etc) is the reason why our implementation uses Enums instead of Strings. Nevertheless for cases when only the name of the weights is available, we offer a method capable of linking Weight names to their Enums:
from torchvision.prototype.models import get_weight
# Weights can be retrieved by name:
assert get_weight("ResNet50_Weights.IMAGENET1K_V1") == ResNet50_Weights.IMAGENET1K_V1
assert get_weight("ResNet50_Weights.IMAGENET1K_V2") == ResNet50_Weights.IMAGENET1K_V2
# Including using the DEFAULT alias:
assert get_weight("ResNet50_Weights.DEFAULT") == ResNet50_Weights.IMAGENET1K_V2
Deprecations
In the new API the boolean pretrained and pretrained_backbone parameters, which were previously used to load weights to the full model or to its backbone, are deprecated. The current implementation is fully backwards compatible as it seamlessly maps the old parameters to the new ones. Using the old parameters to the new builders emits the following deprecation warnings:
>>> model = torchvision.prototype.models.resnet50(pretrained=True)
UserWarning: The parameter 'pretrained' is deprecated, please use 'weights' instead.
UserWarning:
Arguments other than a weight enum or `None` for 'weights' are deprecated.
The current behavior is equivalent to passing `weights=ResNet50_Weights.IMAGENET1K_V1`.
You can also use `weights=ResNet50_Weights.DEFAULT` to get the most up-to-date weights.
Additionally the builder methods require using keyword parameters. The use of positional parameter is deprecated and using them emits the following warning:
>>> model = torchvision.prototype.models.resnet50(None)
UserWarning:
Using 'weights' as positional parameter(s) is deprecated.
Please use keyword parameter(s) instead.
Testing the new API
Migrating to the new API is very straightforward. The following method calls between the 2 APIs are all equivalent:
# Using pretrained weights:
torchvision.prototype.models.resnet50(weights=ResNet50_Weights.IMAGENET1K_V1)
torchvision.models.resnet50(pretrained=True)
torchvision.models.resnet50(True)
# Using no weights:
torchvision.prototype.models.resnet50(weights=None)
torchvision.models.resnet50(pretrained=False)
torchvision.models.resnet50(False)
Note that the prototype features are available only on the nightly versions of TorchVision, so to use it you need to install it as follows:
conda install torchvision -c pytorch-nightly
For alternative ways to install the nightly have a look on the PyTorch download page. You can also install TorchVision from source from the latest main; for more information have a look on our repo.
Accessing state-of-the-art model weights with the new API
If you are still unconvinced about giving a try to the new API, here is one more reason to do so. We’ve recently refreshed our training recipe and achieved SOTA accuracy from many of our models. The improved weights can easily be accessed via the new API. Here is a quick overview of the model improvements:
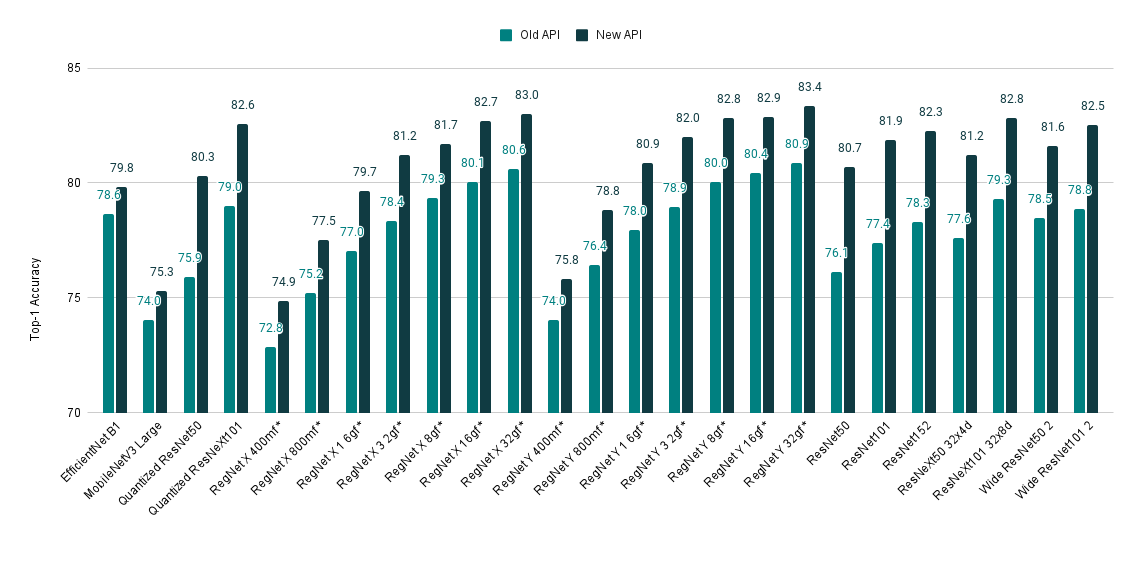
| Model | Old Acc@1 | New Acc@1 |
|---|---|---|
| EfficientNet B1 | 78.642 | 79.838 |
| MobileNetV3 Large | 74.042 | 75.274 |
| Quantized ResNet50 | 75.92 | 80.282 |
| Quantized ResNeXt101 32x8d | 78.986 | 82.574 |
| RegNet X 400mf | 72.834 | 74.864 |
| RegNet X 800mf | 75.212 | 77.522 |
| RegNet X 1 6gf | 77.04 | 79.668 |
| RegNet X 3 2gf | 78.364 | 81.198 |
| RegNet X 8gf | 79.344 | 81.682 |
| RegNet X 16gf | 80.058 | 82.72 |
| RegNet X 32gf | 80.622 | 83.018 |
| RegNet Y 400mf | 74.046 | 75.806 |
| RegNet Y 800mf | 76.42 | 78.838 |
| RegNet Y 1 6gf | 77.95 | 80.882 |
| RegNet Y 3 2gf | 78.948 | 81.984 |
| RegNet Y 8gf | 80.032 | 82.828 |
| RegNet Y 16gf | 80.424 | 82.89 |
| RegNet Y 32gf | 80.878 | 83.366 |
| ResNet50 | 76.13 | 80.858 |
| ResNet101 | 77.374 | 81.886 |
| ResNet152 | 78.312 | 82.284 |
| ResNeXt50 32x4d | 77.618 | 81.198 |
| ResNeXt101 32x8d | 79.312 | 82.834 |
| Wide ResNet50 2 | 78.468 | 81.602 |
| Wide ResNet101 2 | 78.848 | 82.51 |
Please spare a few minutes to provide your feedback on the new API, as this is crucial for graduating it from prototype and including it in the next release. You can do this on the dedicated Github Issue. We are looking forward to reading your comments!
