Hidet is a powerful deep learning compiler that simplifies the process of implementing high-performing deep learning operators on modern accelerators (e.g., NVIDIA GPUs). With the new feature of torch.compile(...) in PyTorch 2.0, integrating a novel compiler into PyTorch is easier than ever - Hidet now can be used as a torch.compile(...) backend to accelerate PyTorch models, making it an attractive option for PyTorch users who want to improve the inference performance of their models, especially for those who also need to implement extremely optimized custom operators.
Using Hidet to Compile A PyTorch Model
To use Hidet in PyTorch, you need to first install the hidet package via pip:
pip install hidet
Hidet is integrated with PyTorch as a torch.compile(...) backend following the Custom Backends tutorial. You can specify hidet as the backend when you compile a model. (Note: requires PyTorch version 2.0+):
torch.compile(..., backend='hidet')
Hidet converts the given PyTorch model in the torch.fx.Graph format into its internal graph representation, and conducts a series of optimizations. Hidet provides a few options to configure the optimizations. For example, we can use hidet.torch.dynamo_config.use_tensor_core(True) to allow Hidet to generate CUDA kernels that leverage the Tensor Cores on NVIDIA GPUs, and use hidet.torch.dynamo_config.search_space(2) to allow Hidet to search for the best operator schedule specific for your hardware and input sizes. More configurations can be found in Hidet’s documentation.
Here’s a complete example of how to use Hidet to compile and optimize a pre-trained ResNet50 model from torchvision:
import hidet
import torch
# Load a pre-trained ResNet50 model
x = torch.randn(1, 3, 224, 224, device='cuda').half()
model = torch.hub.load(
'pytorch/vision:v0.6.0', 'resnet50', pretrained=True
).cuda().half().eval()
# Configure hidet to use tensor core and enable tuning
hidet.torch.dynamo_config.use_tensor_core(True)
hidet.torch.dynamo_config.search_space(2)
# Compile the model using Hidet
model_opt = torch.compile(model, backend='hidet')
# Check correctness
torch.testing.assert_close(actual=model_opt(x), expected=model(x), rtol=1e-2, atol=1e-2)
# Benchmark
from hidet.utils import benchmark_func
print('eager: {:2f}'.format(benchmark_func(lambda: model(x))))
print('hidet: {:2f}'.format(benchmark_func(lambda: model_opt(x))))
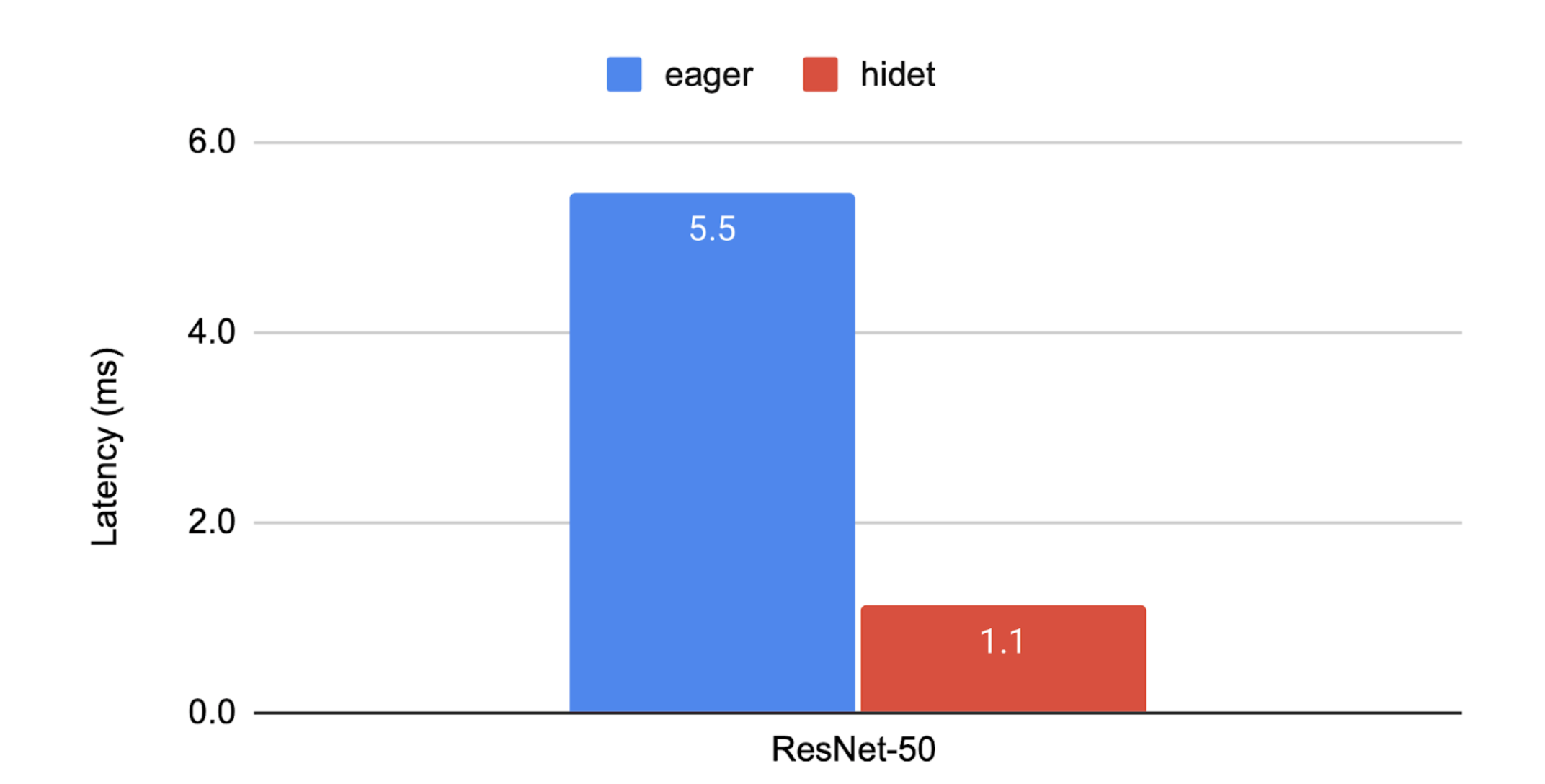
We encourage you to try out the above script on your own NVIDIA GPU(s)! If you run this script on an aws.g5.2xlarge instance, you would get the result shown in the following figure. Hidet achieves the speedup because it could automatically fuse multiple operators, tune operator schedules, and use CUDA Graph to reduce framework-level overhead. More results can be found in the ASPLOS’23 publication of Hidet and our performance tracking
Using Hidet Script to Write Custom Operators
Hidet Script is one approach to implement tensor operators in Python. The following example shows how to implement a naive matrix multiplication using Hidet Script and integrate it as a PyTorch operator.
import torch
import hidet
def matmul(m_size, n_size, k_size):
from hidet.lang import f32, attr
from hidet.lang.cuda import threadIdx, blockIdx, blockDim
with hidet.script_module() as script_module:
@hidet.script
def matmul(
a: f32[m_size, k_size],
b: f32[k_size, n_size],
c: f32[m_size, n_size]
):
attr.cuda_grid_dim = ((m_size + 31) // 32, (n_size + 31) // 32)
attr.cuda_block_dim = (32, 32)
i = threadIdx.x + blockIdx.x * blockDim.x
j = threadIdx.y + blockIdx.y * blockDim.y
if i < m_size and j < n_size:
c[i, j] = 0.0
for k in range(k_size):
c[i, j] += a[i, k] * b[k, j]
ir_module = script_module.ir_module()
func = hidet.driver.build_ir_module(ir_module)
return func
class NaiveMatmul(torch.autograd.Function):
@staticmethod
def forward(ctx, a, b):
m, k = a.shape
k, n = b.shape
c = torch.empty([m, n], dtype=a.dtype, device=a.device)
func = matmul(m, n, k)
func(a, b, c)
return c
a = torch.randn([3, 4], device='cuda')
b = torch.randn([4, 5], device='cuda')
c = NaiveMatmul.apply(a, b)
cc = torch.matmul(a, b)
torch.testing.assert_close(c, cc)
More optimizations can be applied, see the example in our documentation to learn more.
Hidet Script vs. Triton: Triton greatly simplifies the CUDA programming by introducing the tile-based programming model where the parallel execution unit is thread blocks instead of threads. However, this simplification also prevents the tensor program developers from manipulating the fine-grained computation and memory resources (e.g., warps, shared memory) in their preferred ways. It would be challenging to implement an optimization that requires fine-grained control of these resources using Triton if it has not been implemented by the Triton compiler itself. Hidet Script, on the other hand, simplifies tensor programming while still enabling users to implement their own optimizations with extensive flexibility. It’s worth noting that the more granular control of Hidet Script also brings added complexity compared to Triton.
More about Hidet
Hidet originates from a research project led by the EcoSystem lab at the University of Toronto (UofT) and AWS. The authors propose a new way, named the task-mapping programming paradigm, to construct tensor programs. It aims to simplify the tensor programming without sacrificing any optimization opportunity. Now, Hidet is an open-source project, jointly supported by CentML and the EcoSystem lab, that aims to provide an efficient solution to end-to-end inference on modern accelerators (e.g., NVIDIA GPUs).
Additional Resources
- GitHub Repository: https://github.com/hidet-org/hidet
- Hidet’s Documentation: https://docs.hidet.org
- ASPLOS ’23 Publication: https://dl.acm.org/doi/10.1145/3575693.3575702
- ASPLOS ’23 Tutorial: https://centml.github.io/asplos23-tutorial/
Acknowledgement
We would like to thank Jerry Park, Mark Saroufim, Jason Liang and Helen Suk for their valuable help on preparing the blog post and feedback on the text. We also would like to thank Nikita Shulga, Jason Ansel, and Dmytro Dzhulgakov for reviewing and improving our PR https://github.com/pytorch/pytorch/pull/93873 on the 3rd-party dynamo backend registration.
