Introduction
Complete and accurate clinical documentation is an essential tool for tracking patient care. It allows for treatment plans to be shared among care teams to aid in continuity of care and ensures a transparent and effective process for reimbursement.
Physicians are responsible for documenting patient care. Traditional clinical documentation methods have resulted in a sub-par patient-provider experience, less time interacting with patients, and decreased work-life balance. A significant amount of physicians’ time is spent in front of the computer doing administrative tasks. As a result, patients are less satisfied with the overall experience, and physicians, who prepare for years studying medicine, cannot practice at the top of their license and are burned out. Every hour physicians provide direct clinical face time to patients results in nearly two additional hours spent on EHR and desk work within the clinic day. Outside office hours, physicians spend another 1 to 2 hours of personal time each night doing additional computer and other clerical work.
- 42% of all physicians reported having burnout. – Medscape
- The problem has grown worse due to the pandemic with 64% of U.S. physicians now reporting burnout. - AAFP
- “Too many bureaucratic tasks e.g., charting and paperwork” is the leading contribution to burnout, increased computerization ranks 4th. - Medscape
- 75% of U.S. Consumers Wish Their Healthcare Experiences Were More Personalized,- Business Wire
- 61% of patients would visit their healthcare provider more often if the communication experience felt more personalized. – Business Wire
Physician burnout is one of the primary causes for increased medical errors, malpractice suits, turnover, and decreased access to care. Burnout leads to an increase in healthcare costs and a decrease in overall patient satisfaction. Burnout costs the United States $4.6 billion a year.
What can we do to bring back trust, joy, and humanity to the delivery of healthcare? A significant portion of the administrative work consists of entering patient data into Electronic Health Records (EHRs) and creating clinical documentation. Clinical documentation is created from information already in the EHR as well as from the patient-provider encounter conversation.
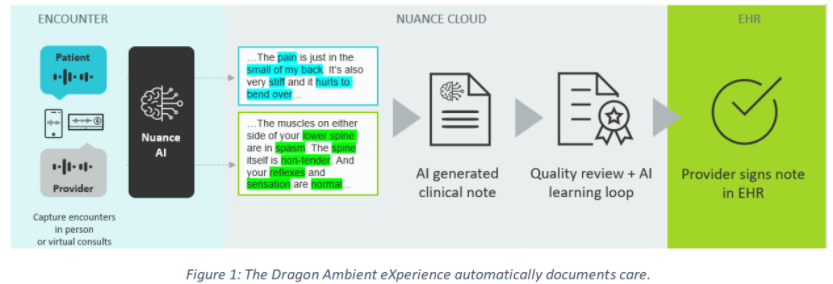
This article will showcase how the Nuance Dragon Ambient eXperience (DAX), an AI-powered, voice-enabled, ambient clinical intelligence solution, automatically documents patient encounters accurately and efficiently at the point of care and the technologies that enable it.
Nuance DAX enhances the quality of care and patient experience, increases provider efficiency and satisfaction, and improves financial outcomes. It can be used in office and telehealth settings in all ambulatory specialties, including primary and urgent care.
Natural Language Processing
Natural Language Processing (NLP) is one of the most challenging fields in Artificial Intelligence (AI). It comprehends a set of algorithms that allow computers to understand or generate the language used by humans. These algorithms can process and analyze vast amounts of natural language data from different sources (either sound or text) to build models that can understand, classify, or even generate natural language as humans would. Like other fields in AI, NLP has significantly progressed thanks to the advent of Deep Learning (DL), which has resulted in models that can obtain results on par with humans in some tasks.
These advanced NLP techniques are being applied in healthcare. During a typical patient-provider encounter, a conversation ensues where the doctor constructs, through questions and answers, a chronological description of the development of the patient’s presenting illness or symptoms. A physician examines the patient and makes clinical decisions to establish a diagnosis and determine a treatment plan. This conversation, and data in the EHR, provide the required information for physicians to generate the clinical documentation, referred to as medical reports.
Two main NLP components play a role in automating the creation of clinical documentation. The first component, Automatic Speech Recognition (ASR), is used to translate speech into text. It takes the audio recording of the encounter and generates a conversation transcription (cf. Figure 2). The second component, Automatic Text Summarization, helps generate summaries from large text documents. This component is responsible for understanding and capturing the nuances and most essential aspects from the transcribed conversation into a final report in narrative form (cf. Figure 3), structured form, or a combination of both.
We will focus on this second component, Automatic Text Summarization, which is a difficult task with many challenges:
- Its performance is tied to the ASR quality from multiple speakers (noisy input).
- The input is conversational in nature and contains layman’s terms.
- Protected Health Information (PHI) regulations limit medical data access.
- The information for one output sentence is potentially spread across multiple conversation turns.
- There is no explicit sentence alignment between input and output.
- Various medical specialties, encounter types, and EHR systems constitute a broad and complex output space.
- Physicians have different styles of conducting encounters and have their preferences for medical reports; there is no standard.
- Standard summarization metrics might differ from human judgment of quality.

Figure 2: Transcript of a patient-doctor conversation
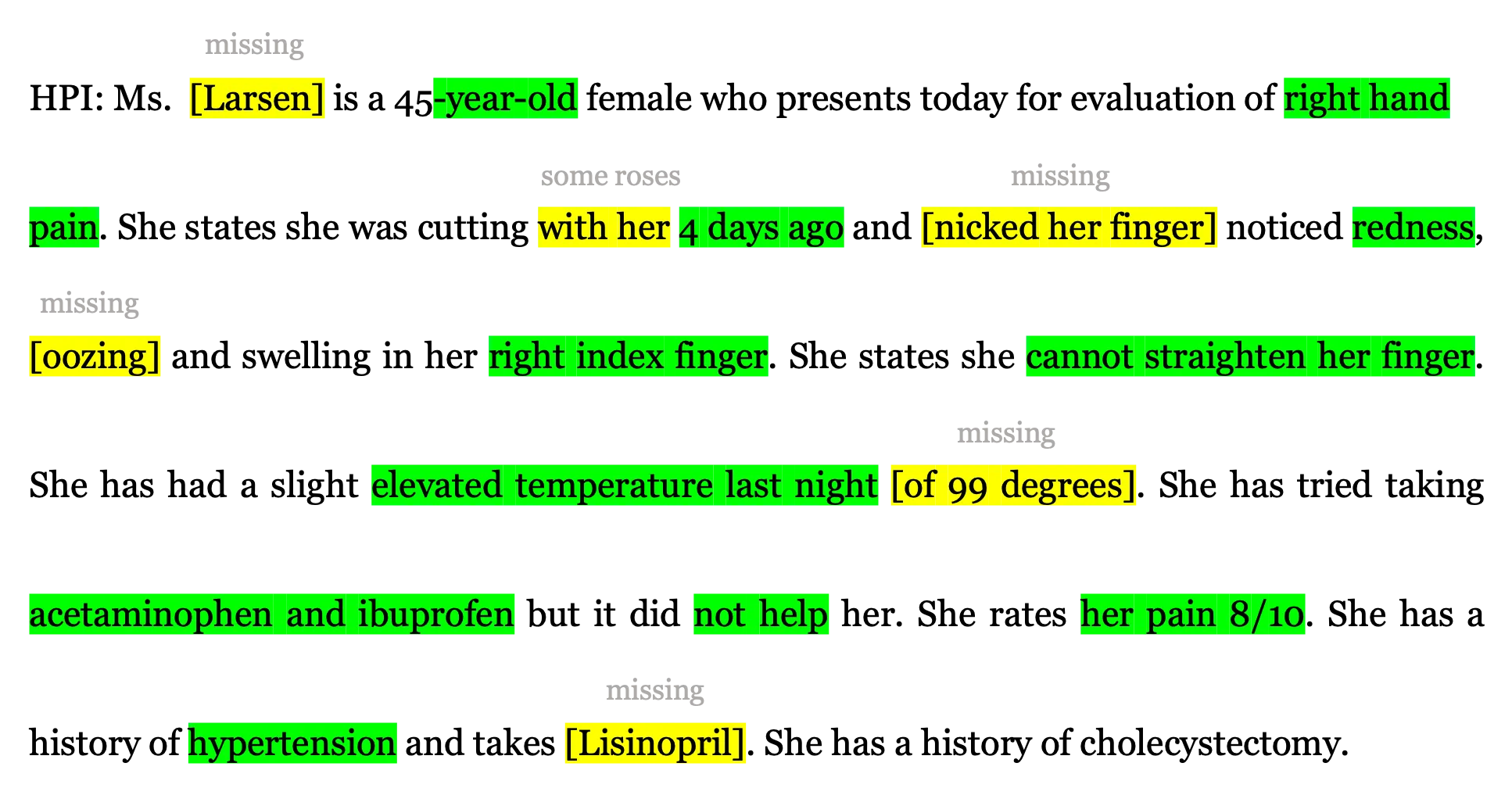
Figure 3: Excerpt of an AI-generated medical report. HPI stands for History of present illness.
Text Summarization with PyTorch and Fairseq
PyTorch is an open-source machine learning framework developed by Facebook that helps researchers prototype Deep Learning models. The Fairseq toolkit is built on top of PyTorch and focuses on sequence generation tasks, such as Neural Machine Translation (NMT) or Text Summarization. Fairseq features an active community that is continuously providing reference implementations of state-of-the-art models. It contains many built-in components (model architectures, modules, loss functions, and optimizers) and is easily extendable with plugins.
Text summarization constitutes a significant challenge in NLP. We need models capable of generating a short version of a document while retaining the key points and avoiding uninformative content. These challenges can be addressed with different approaches. 1). Abstractive text summarization aimed at training models that can generate a summary in narrative form. 2). Extractive methods where the models are trained to select the most important parts from the input text. 3). A combination of the two, where the essential parts from the input are selected and then summarized in an abstractive fashion. Hence, summarization can be accomplished via a single end-to-end network or as a pipeline of extractive and abstractive components. To that end, Fairseq provides all the necessary tools to be successful in our endeavor. It features either end-to-end models such as the classical Transformer, different types of Language Models and pre-trained versions that enable researchers to focus on what matters most—to build state-of-the-art models that generate valuable reports.
However, we are not just summarizing the transcribed conversation; we generate high-quality medical reports, which have many considerations.
- Every section of a medical report is different in terms of content, structure, fluency, etc.
- All medical facts mentioned in the conversation should be present in the report, for example, a particular treatment or dosage.
- In the healthcare domain, the vocabulary is extensive, and models need to deal with medical terminology.
- Patient-doctor conversations are usually much longer than the final report.
All these challenges require our researchers to run a battery of extensive experiments. Thanks to the flexibility of PyTorch and Fairseq, their productivity has greatly increased. Further, the ecosystem offers an easy path from ideation, implementation, experimentation, and final roll-out to production. Using multiple GPUs or CPUs is as simple as providing an additional argument to the tools, and because of the tight Python integration, PyTorch code can be easily debugged.
In our continuous effort to contribute to the open-source community, features have been developed at Nuance and pushed to the Fairseq GitHub repository. These try to overcome some of the challenges mentioned such as, facilitating copying of, especially rare or unseen, words from the input to summary, training speedups by improving Tensor Core utilization, and ensuring TorchScript compatibility of different Transformer configurations. Following, we will show an example of how to train a Transformer model with a Pointer Generator mechanism (Transformer-PG), which can copy words from the input.
How to build a Transformer model with a Pointer Generator mechanism
In this step-by-step guide, it is assumed the user has already installed PyTorch and Fairseq.
1. Create a vocabulary and extend it with source position markers:
These markers will allow the model to point to any word in the input sequence.
vocab_size=<vocab_size>
position_markers=512
export LC_ALL=C
cat train.src train.tgt |
tr -s '[:space:]' '\n' |
sort |
uniq -c |
sort -k1,1bnr -k2 |
head -n "$((vocab_size - 4))" |
awk '{ print $2 " " $1 }' > dict.pg.txt
python3 -c "[print('<unk-{}> 0'.format(n)) for n in range($position_markers)]" >> dict.pg.txt
This will create a file “dict.pg.txt” that contains the <vocab_size> most frequent words followed by 512 position markers named from “<unk-0>” to “<unk-511>”.
In case we have an input like
src = "Hello, I'm The Dogtor"
it could happen that our model has been trained without the word “Dogtor” in its vocabulary. Therefore, when we feed this sequence into the model, it should be converted to:
src = "Hello, I'm The <unk-3>"
Now, “<unk-3>” is part of our vocabulary and could be predicted by the model (this is where the pointer-generator comes in). In such a case, we will only need to post-process the output to replace “<unk-3>” by the word at input position 3.
2. Preprocess the text data to replace unknown words by its positional markers:
We can use the scripts from https://github.com/pytorch/fairseq/tree/master/examples/pointer_generator.
# Considering we have our data in:
# train_src = /path/to/train.src
# train_tgt = /path/to/train.tgt
# valid_src = /path/to/valid.src
# valid_tgt = /path/to/valid.tgt
./preprocess.py --source /path/to/train.src \
--target /path/to/train.tgt \
--vocab <(cut -d' ' -f1 dict.pg.txt) \
--source-out /path/to/train.pg.src \
--target-out /path/to/train.pg.tgt
./preprocess.py --source /path/to/valid.src \
--target /path/to/valid.tgt \
--vocab <(cut -d' ' -f1 dict.pg.txt) \
--source-out /path/to/valid.pg.src \
--target-out /path/to/valid.pg.tgt
./preprocess.py --source /path/to/test.src \
--vocab <(cut -d' ' -f1 dict.pg.txt) \
--source-out /path/to/test.pg.src
3. Now let’s binarize the data, so that it can be processed faster:
fairseq-preprocess --task "translation" \
--source-lang "pg.src" \
--target-lang "pg.tgt" \
--trainpref /path/to/train \
--validpref /path/to/valid \
--srcdict dict.pg.txt \
--cpu \
--joined-dictionary \
--destdir <data_dir>
You might notice the type of task is “translation”. This is because there is no “summarization” task available; we could understand it as a kind of NMT task where the input and output languages are shared and the output (summary) is shorter than the input.
4. Now we can train the model:
fairseq-train <data_dir> \
--save-dir <model_dir> \
--task "translation" \
--source-lang "src" \
--target-lang "tgt" \
--arch "transformer_pointer_generator" \
--max-source-positions 512 \
--max-target-positions 128 \
--truncate-source \
--max-tokens 2048 \
--required-batch-size-multiple 1 \
--required-seq-len-multiple 8 \
--share-all-embeddings \
--dropout 0.1 \
--criterion "cross_entropy" \
--optimizer adam \
--adam-betas '(0.9, 0.98)' \
--adam-eps 1e-9 \
--update-freq 4 \
--lr 0.004 \
# Pointer Generator
--alignment-layer -1 \
--alignment-heads 1 \
--source-position-markers 512
This configuration makes use of features Nuance has contributed back to Fairseq:
- Transformer with a Pointer Generator mechanism to facilitate copying of words from the input.
- Sequence length padded to a multiple of 8 to better use tensor cores and reduce training time.
5. Now let’s take a look at how to generate a summary with our new medical report generation system:
import torch
from examples.pointer_generator.pointer_generator_src.transformer_pg import TransformerPointerGeneratorModel
# Patient-Doctor conversation
input = "[doctor] Lisa Simpson, thirty six year old female, presents to the clinic today because " \
"she has severe right wrist pain"
# Load the model
model = TransformerPointerGeneratorModel.from_pretrained(data_name_or_path=<data_dir>,
model_name_or_path=<model_dir>,
checkpoint_file="checkpoint_best.pt")
result = model.translate([input], beam=2)
print(result[0])
Ms. <unk-2> is a 36-year-old female who presents to the clinic today for evaluation of her right wrist.
6. Alternatively, we can use fairseq-interactive and a postprocessing tool to substitute positional unknown tokens by its words from the input:
fairseq-interactive <data_dir> \
--batch-size <batch_size> \
--task translation \
--source-lang src \
--target-lang tgt \
--path <model_dir>/checkpoint_last.pt \
--input /path/to/test.pg.src \
--buffer-size 20 \
--max-len-a 0 \
--max-len-b 128 \
--beam 2 \
--skip-invalid-size-inputs-valid-test | tee generate.out
grep "^H-" generate.out | cut -f 3- > generate.hyp
./postprocess.py \
--source <(awk 'NF<512' /path/to/test.pg.src) \
--target generate.hyp \
--target-out generate.hyp.processed
Now we have the final set of reports in “generate.hyp.processed”, with “<unk-N>” replaced by the original word from the input sequence.
Model Deployment
PyTorch offers great flexibility in modeling and a rich surrounding ecosystem. However, while several recent articles have suggested that the use of PyTorch in research and academia may be close to surpassing TensorFlow, there seems to be an overall sense of TensorFlow being the preferred platform for deployment to production. Is this still the case in 2021? Teams looking to serve their PyTorch models in production have a few options.
Before describing our journey, let’s take a brief detour and define the term model.
Models as computation graphs
A few years back, it was still common for machine learning toolkits to support only particular classes of models of a rather fixed and rigid structure, with only a few degrees of freedom (like the kernel of a support vector machine or the number of hidden layers of a neural network). Inspired by foundational work in Theano, toolkits like Microsoft’s CNTK or Google’s TensorFlow were among the first to popularize a more flexible view on models, as computation graphs with associated parameters that can be estimated from data. This view blurred the boundaries between popular types of models (such as DNNs or SVMs), as it became easy to blend the characteristics of each into your type of graph. Still, such a graph had to be defined upfront before estimating its parameters, and it was pretty static. This made it easy to save models to a self-contained bundle, like a TensorFlow SavedModel (such a bundle simply contains the structure of the graph, as well as the concrete values of the estimated parameters). However, debugging such models can be difficult because the statements in the Python code that build the graph are logically separate from the lines that execute it. Researchers also long for easier ways of expressing dynamic behavior, such as the computation steps of the forward pass of a model being conditionally dependent on its input data (or its previous output).
Most recently, the above limitations have led to a second revolution spearheaded by PyTorch and TensorFlow 2. The computation graph is no longer defined explicitly. Instead, it will be populated implicitly as the Python code executes operations on tensor arguments. An essential technique that powers this development is automatic differentiation. As the computation graph is being built implicitly while executing the steps of the forward pass, all the necessary data will be tracked for later computation of the gradient concerning the model parameters. This allows for great flexibility in training a model, but it raises an important question. If the computation happening inside a model is only implicitly defined through our Python code’s steps as it executes concrete data, what is it that we want to save as a model? The answer – at least initially – was the Python code with all its dependencies, along with the estimated parameters. This is undesirable for practical reasons. For instance, there is a danger that the team working on model deployment does not exactly reproduce the Python code dependencies used during training, leading to subtly divergent behavior. The solution typically consists of combining two techniques, scripting and tracing, that is, extra annotations in your Python code and execution of your code on exemplary input data, allowing PyTorch to define and save the graph that should be executed during later inference on new, unseen data. This requires some discipline by whoever creates the model code (arguably voiding some of the original flexibility of eager execution), but it results in a self-contained model bundle in TorchScript format. The solution in TensorFlow 2 is remarkably similar.
Serving our report generation models
Our journey in deploying the report generation models reflects the above discussion. We started out serving our models by deploying the model code and its dependencies along with the parameter checkpoints in a custom Docker image exposing a gRPC service interface. However, we soon noticed that it became error-prone to replicate the exact code and environment used by the modeling team while estimating the parameters. Moreover, this approach prevented us from leveraging high-performance model serving frameworks like NVIDIA’s Triton, which is written in C++ and requires self-contained models that can be used without a Python interpreter. At this stage, we were facing a choice between attempting to export our PyTorch models to ONNX or TorchScript format. ONNX is an open specification for representing machine learning models that increasingly finds adoption. It is powered by a high-performance runtime developed by Microsoft (ONNX Runtime). While we were able to achieve performance acceleration for our TensorFlow BERT-based model using ONNX Runtime, at the time one of our PyTorch model required some operators that weren’t yet supported in ONNX. Rather than implement these using custom operators, we decided to look into TorchScript for the time being.
A maturing ecosystem
Is it all roses? No, it has been a rockier journey than we expected. We encountered what seems to be a memory leak in the MKL libraries used by PyTorch while serving the PyTorch code directly. We encountered deadlocks in trying to load multiple models from multiple threads. We had difficulties exporting our models to ONNX and TorchScript formats. Models would not work out-of-the-box on hardware with multiple GPUs, they always accessed the particular GPU device on which they were exported. We encountered excessive memory usage in the Triton inference server while serving TorchScript models, which we found out was due to automatic differentiation accidentally being enabled during the forward pass. However, the ecosystem keeps improving, and there is a helpful and vibrant open-source community eager to work with us to mitigate such issues.
Where to go from here? For those that require the flexibility of serving PyTorch code directly, without going through the extra step of exporting self-contained models, it is worth pointing out that the TorchServe project now provides a way of bundling the code together with parameter checkpoints into a single servable archive, greatly reducing the risk of code and parameters running apart. To us, however, exporting models to TorchScript has proven beneficial. It provides a clear interface between modeling and deployment teams, and TorchScript further reduces the latency when serving models on GPU via its just-in-time compilation engine.
Scaling at large and the future
Finally, efficient deployment to the cloud is about more than just computing the response of a single model instance efficiently. Flexibility is needed in managing, versioning and updating models. High-level scalability must be achieved via techniques such as load-balancing, horizontal scaling and vertical scaling. If many models are involved, scale-to-zero quickly becomes a topic as it is unacceptable to pay for serving models that do not answer any requests. Providing such extra functionality on top of a low-level inference server like Triton is the job of an orchestration framework. After gaining some first experience with KubeFlow, to that end, we decided to turn our attention to Azure ML, which provides similar functionality but integrates more deeply with the Azure platform, on which we crucially rely for large parts of our technology stack already. This part of our journey has just begun.
Conclusion
Academia has long recognized that we are “standing on the shoulders of giants.” As Artificial Intelligence is maturing from a scientific discipline into technology, the same spirit of collaboration that originally fueled its scientific foundation has carried over into the world of software engineering. Open-source enthusiasts join technology companies worldwide to build open software ecosystems that allow for new angles at solving some of the most pressing challenges of modern society. In this article, we’ve taken a look at Nuance’s Dragon Ambient eXperience, an AI-powered, voice-enabled solution that automatically documents patient care, reducing healthcare providers’ administrative burdens. Nuance DAX improves the patient-provider experience, reduces physician burnout, and improves financial outcomes. It brings back trust, joy, and humanity to the delivery of healthcare. Fairseq and PyTorch have proven to be an incredible platform for powering this AI technology, and in turn, Nuance has contributed back some of its innovations in this space. For further reading, we invite you to take a look at our recent ACL publication and the Nuance “What’s Next” blog.
