Supported in PyTorch 2.0 as a beta feature, oneDNN Graph leverages aggressive fusion patterns to accelerate inference on x86-64 machines, especially Intel® Xeon® Scalable processors.
oneDNN Graph API extends oneDNN with a flexible graph API to maximize the optimization opportunity for generating efficient code on AI hardware. It automatically identifies the graph partitions to be accelerated via fusion. The fusion patterns focus on fusing compute-intensive operations such as convolution, matmul, and their neighbor operations for both inference and training use cases.
In PyTorch 2.0 and beyond, oneDNN Graph can help accelerate inference on x86-64 CPUs (primarily, Intel Xeon processor-based machines) with Float32 and BFloat16 (with PyTorch’s Automatic Mixed Precision support) datatypes. With BFloat16, speedup is limited to machines that support AVX512_BF16 ISA (Instruction Set Architecture), as well as machines that also support AMX_BF16 ISA.
oneDNN Graph Usage
From a user’s perspective, the usage is quite simple and intuitive, with the only change in code being an API invocation. To leverage oneDNN Graph with JIT-tracing, a model is profiled with an example input as shown below in Figure 1.
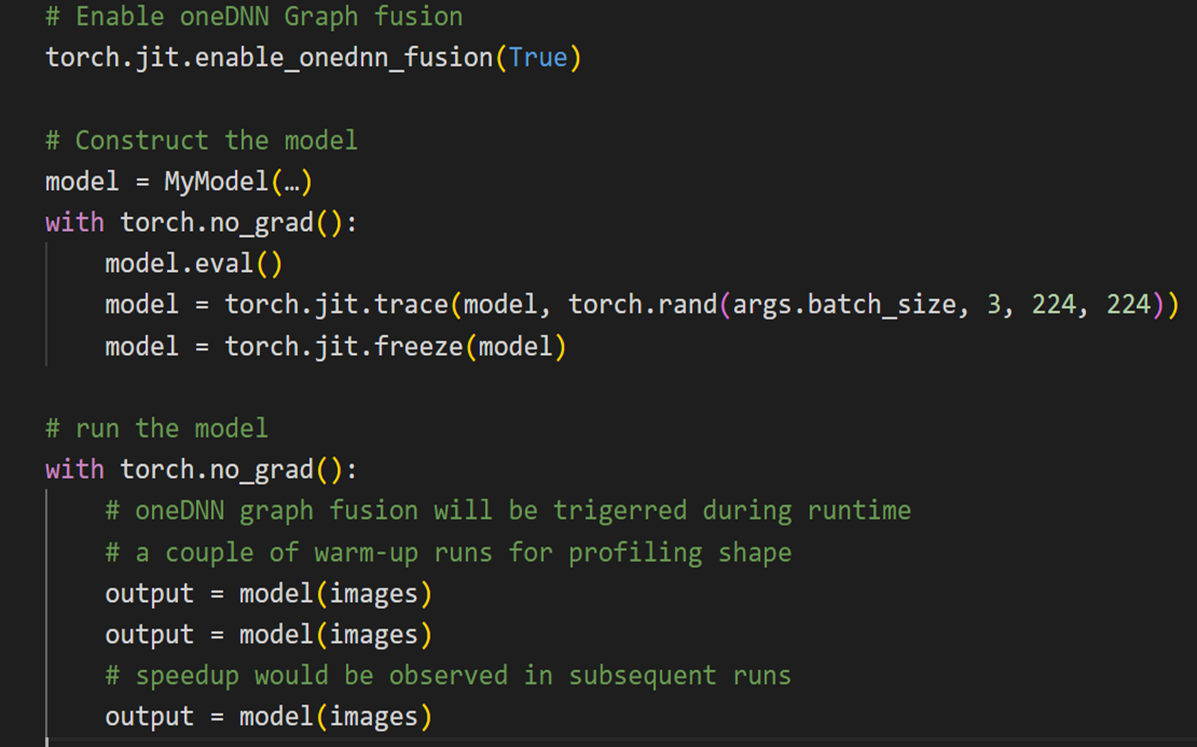
Fig. 1: A code-snippet that demonstrates using oneDNN Graph
oneDNN Graph receives the model’s graph and identifies candidates for operator-fusion with respect to the input shape of the example input. Currently, only static shapes are supported. This means that any other input shape would neither be supported nor receive any performance-benefit.
Measurements
To ensure reproducibility of results, we used a fork of TorchBench to measure inference speed-up of some Vision models on an AWS m7i.16xlarge instance, which uses 4th Gen Intel® Xeon® Scalable processors.
The baseline for comparison was torch.jit.optimize_for_inference which only supports Float32 datatype. The batch-size for each model was based on the respective batch size being used for them in TorchBench.
In Figure 2, we depict the inference speedup of using oneDNN Graph over PyTorch alone. The geomean speedup with oneDNN Graph for Float32 datatype was 1.24x, and the geomean speedup for BFloat16 datatype was 3.31x1.
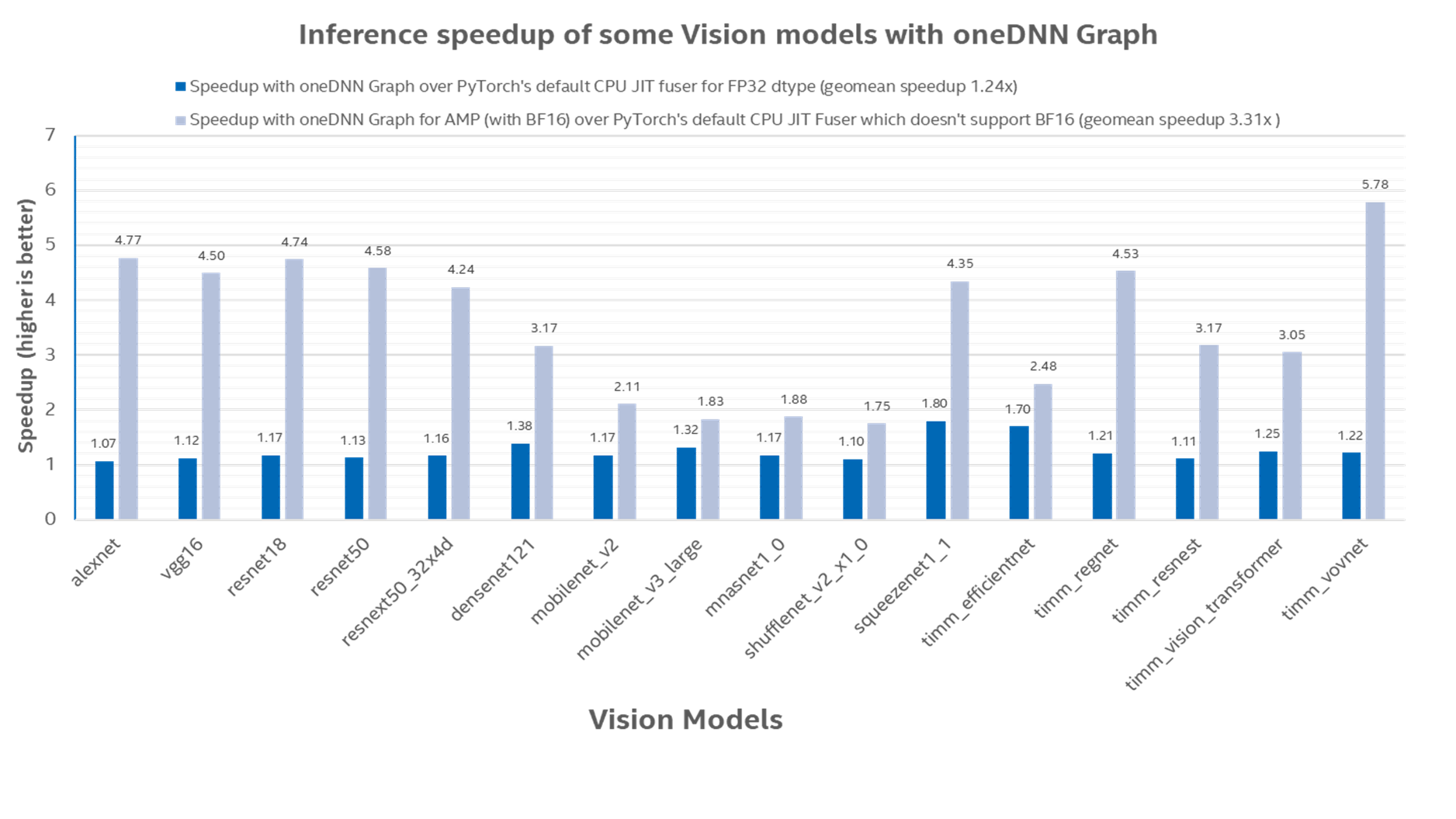
Fig. 2: Inference speedup with oneDNN Graph over default CPU JIT Fuser (which only uses Float32 datatype)
Future work
oneDNN Graph is currently supported in PyTorch through TorchScript, but work is already underway by Intel to integrate it with the Inductor-CPU backend as a prototype feature in a future PyTorch release and Dynamo make supporting dynamic shapes easier with PyTorch, and we would like to introduce Dynamic shape support with Inductor-CPU. We also plan to add int8 quantization support.
Acknowledgements
The results presented in this blog are a joint effort between Meta and the Intel PyTorch team. Special thanks to Elias Ellison from Meta who spent precious time thoroughly reviewing the PRs and gave us helpful feedback.
