The PyTorch 2.0 release includes a new high-performance implementation of the PyTorch Transformer API with the goal of making training and deployment of state-of-the-art Transformer models affordable. Following the successful release of “fastpath” inference execution (“Better Transformer”), this release introduces high-performance support for training and inference using a custom kernel architecture for scaled dot product attention (SPDA).
You can take advantage of the new fused SDPA kernels either by calling the new SDPA operator directly (as described in the SDPA tutorial), or transparently via integration into the pre-existing PyTorch Transformer API. All features of the PyTorch Transformer API will continue to work compatibly, with many features mapped to high-performance SDPA kernels, while other features are impossible to support with higher performance (e.g., need_weights, as per below) while expanded high-performance support for other features may still be under active development.
Similar to the “fastpath” architecture, custom kernels are fully integrated into the PyTorch Transformer API – thus, using the native Transformer and MultiHeadAttention API will enable users to transparently see significant speed improvements. Unlike the “fastpath” architecture, the newly introduced “custom kernels” support many more use cases including models using Cross-Attention, Transformer Decoders, and for training models, in addition to the existing fastpath inference for fixed and variable sequence length Transformer Encoder and Self Attention use cases.
To take full advantage of different hardware models and Transformer use cases, multiple SDPA custom kernels are supported, with custom kernel selection logic that will pick the highest-performance kernel for a given model and hardware type. In particular, the first custom kernels included with the PyTorch 2.0 release are the Flash Attention kernel (sdpa_flash, for 16-bit floating point training and inference on Nvidia GPUs with SM80+ architecture level) and the xFormers memory-efficient attention kernel (sdpa_mem_eff, for 16-bit and 32-bit floating point training and inference on a broad range of Nvidia GPUs). A general-purpose kernel sdpa_math provides an implementation when the custom kernels are not applicable.
As mentioned, custom kernels provide a wider range of support for execution scenarios To ensure efficient execution (e,g., to use GPU tensor cores), model configurations need to meet a small number of requirements. This list of requirements will evolve over time, prospectively relaxing constraints limiting the usage of currently supported custom kernels, or providing additional kernels in the future.
For the most up to date list of custom kernels and dispatch constraints, you can refer to sdp_utils.h. As of PyTorch 2.0, the existing fused SDPA kernels have the following constraints:
- Flash Attention only supports 16 bit floating point data types (float16 and bfloat16).
- The head dimension must be a multiple of 8 for 16-bit floating point numbers and a multiple of 4 for 32-bit floating point numbers. At present, the maximum head_dim support for the Flash Attention custom kernel is 128.
- The CUDA architecture level must be sm5x or better for the mem_efficient kernel, and sm80 for Flash Attention.
- Flash Attention supports arbitrary dropout, in PyTorch 2.0 the mem_efficient kernel does not support dropout (i.e., dropout must be set to zero for this kernel to be selected in PyTorch 2.0).
- To support variable-sequence length batches, all SDPA kernels support Nested Tensor inputs that combine input data and padding information using variable sequence length tensors for forward. (You can find more information about Nested Tensors in the Nested Tensor tutorial.)
- You can specify both a key_padding_mask and an attn_mask by combining them before passing them to the SDPA operator. In particular, you can use the per-batch-element key padding mask of the nn.Transformer API to implement training for variable-sequence length inputs in a batch.
- At present, the only attention mask supported by fused kernel implementation is the causal mask commonly used for training. To specify the causal mask in custom kernels, it must be specified with the is_causal boolean and attn_mask must be None.
- Support for Nested Tensors is still under development. Specifically, in PyTorch 2.0, only the sdpa_math kernel supports training with Nested Tensors. Also, PyTorch 2.0 does not support Nested Tensors as part of code being compiled with torch.compile().
- The SDPA operator does not support returning averaged attention weights because computing them defeats the optimizations that enabled fused kernels to execute more efficiently. The argument need_weights for torch.nn.MultiheadAttention’s forward function defaults to True. In order to use the fused kernels, need_weights needs to be set to need_weights=False.
We find that an attention mask is rarely used in real-world applications, except for the causal mask during training. Consequently, we reduce kernel complexity and compute cost by building in the option to use a causal mask as attention mask, and select this new capability with the is_causal parameter introduced in conjunction with the new SDPA operator.
Providing the is_causal Boolean flag for the frequently used causal mask also obviates the expensive and memory-intensive allocation of a causal mask, increasing training memory efficiency by allowing more memory to be used for large batch sizes, and reduce memory bandwidth and cache contention – which are both at a premium in GPU accelerators – by not needing to load an attention mask tensor.
If the constraints of none of the available custom kernels are met, then training falls back to using the default sdpa_math kernel, implementing the mathematical equations for scaled dot product attention using a sequence of PyTorch operator to implement SDPA. This is the most general “catch-all” fallback kernel to ensure successful training for all models.
In addition to the existing Transformer API, model developers may also use the scaled dot product attention kernels directly by calling the new scaled_dot_product_attention() operator. This operator may be used to efficiently implement multi-head attention by combining it with in-projection and outprojection, as described in the SDPA tutorial.
In addition to adding custom kernels, Accelerated PyTorch 2 Transformers are integrated with PyTorch 2.0 compilation. To use your model while benefiting from the additional acceleration of PT2-compilation (for inference or training), pre-process the model with
model = torch.compile(model)
We have achieved major speedups for training transformer models and in particular large language models with Accelerated PyTorch 2 Transformers using a combination of custom kernels and torch.compile().
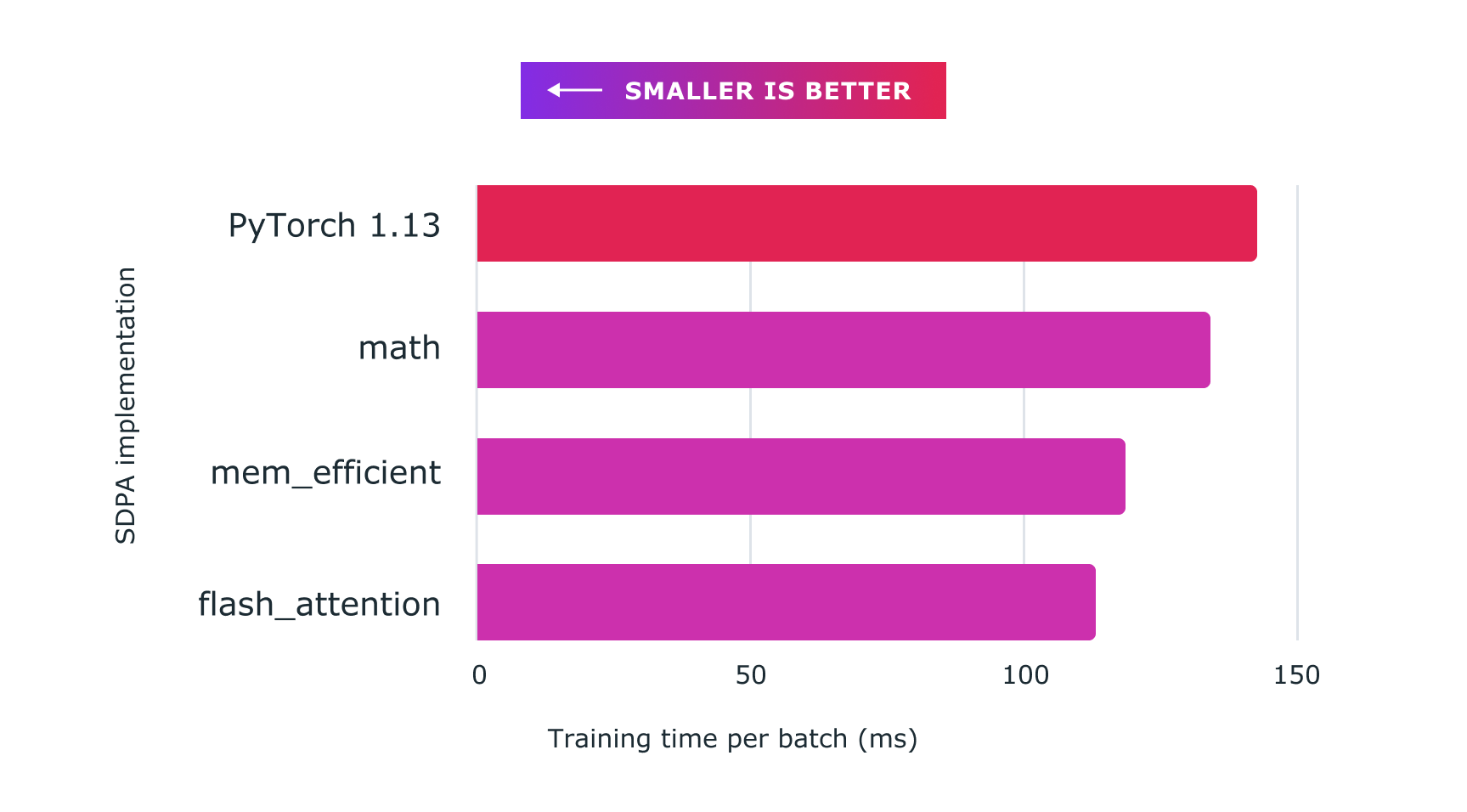 Figure: Using scaled dot product attention with custom kernels and torch.compile delivers significant speedups for training large language models, such as for nanoGPT shown here.
Figure: Using scaled dot product attention with custom kernels and torch.compile delivers significant speedups for training large language models, such as for nanoGPT shown here.
Finally, because the custom kernels are much more memory efficient, try to increase the size of training batches to achieve faster training with increased batch size.
In addition to automatic kernel selection, a context manager enables developers to override the kernel selection algorithm – this is not required for day to day operation, but enables developers to debug their code as well as enable performance engineers to override kernel selection. The SDPA tutorial provides additional information on using the SDPA context manager.
In addition to availability as part of the nn.Transformer API, Accelerated PyTorch 2 Transformer custom kernels are also available in conjunction with the torchtext, torchvision, and fairseq domain libraries with the launch of PyTorch 2.0.
