PyTorch 2.0 has just been released. Its flagship new feature is torch.compile(), a one-line code change that promises to automatically improve performance across codebases. We have previously checked on that promise in Hugging Face Transformers and TIMM models, and delved deep into its motivation, architecture and the road ahead.
As important as torch.compile() is, there’s much more to PyTorch 2.0. Notably, PyTorch 2.0 incorporates several strategies to accelerate transformer blocks, and these improvements are very relevant for diffusion models too. Techniques such as FlashAttention, for example, have become very popular in the diffusion community thanks to their ability to significantly speed up Stable Diffusion and achieve larger batch sizes, and they are now part of PyTorch 2.0.
In this post we discuss how attention layers are optimized in PyTorch 2.0 and how these optimization are applied to the popular 🧨 Diffusers library. We finish with a benchmark that shows how the use of PyTorch 2.0 and Diffusers immediately translates to significant performance improvements across different hardware.
Update (June 2023): a new section has been added to show dramatic performance improvements of torch.compile() with the latest version of PyTorch (2.0.1), after going through the process of fixing graph breaks in the diffusers codebase. A more detailed analysis of how to find and fix graph breaks will be published in a separate post.
Accelerating transformer blocks
PyTorch 2.0 includes a scaled dot-product attention function as part of torch.nn.functional. This function encompasses several implementations that can be applied depending on the inputs and the hardware in use. Before PyTorch 2.0, you had to search for third-party implementations and install separate packages in order to take advantage of memory optimized algorithms, such as FlashAttention. The available implementations are:
- FlashAttention, from the official FlashAttention project.
- Memory-Efficient Attention, from the xFormers project.
- A native C++ implementation suitable for non-CUDA devices or when high-precision is required.
All these methods are available by default, and PyTorch will try to select the optimal one automatically through the use of the new scaled dot-product attention (SDPA) API. You can also individually toggle them for finer-grained control, see the documentation for details.
Using scaled dot-product attention in diffusers
The incorporation of Accelerated PyTorch 2.0 Transformer attention to the Diffusers library was achieved through the use of the set_attn_processor method, which allows for pluggable attention modules to be configured. In this case, a new attention processor was created, which is enabled by default when PyTorch 2.0 is available. For clarity, this is how you could enable it manually (but it’s usually not necessary since diffusers will automatically take care of it):
from diffusers import StableDiffusionPipeline
from diffusers.models.cross_attention import AttnProcessor2_0
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
pipe.to("cuda")
pipe.unet.set_attn_processor(AttnProcessor2_0())
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
Stable Diffusion Benchmark
We ran a number of tests using accelerated dot-product attention from PyTorch 2.0 in Diffusers. We installed diffusers from pip and used nightly versions of PyTorch 2.0, since our tests were performed before the official release. We also used torch.set_float32_matmul_precision('high') to enable additional fast matrix multiplication algorithms.
We compared results with the traditional attention implementation in diffusers (referred to as vanilla below) as well as with the best-performing solution in pre-2.0 PyTorch: PyTorch 1.13.1 with the xFormers package (v0.0.16) installed.
Results were measured without compilation (i.e., no code changes at all), and also with a single call to torch.compile() to wrap the UNet module. We did not compile the image decoder because most of the time is spent in the 50 denoising iterations that run UNet evaluations.
Results in float32
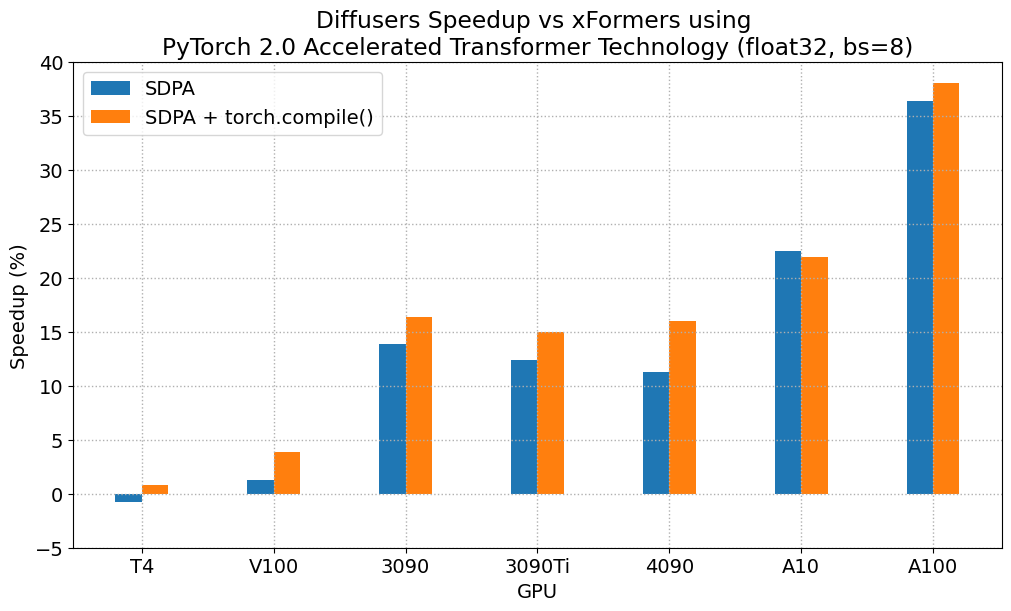
The following figures explore performance improvement vs batch size for various representative GPUs belonging to different generations. We collected data for each combination until we reached maximum memory utilization. Vanilla attention runs out of memory earlier than xFormers or PyTorch 2.0, which explains the missing bars for larger batch sizes. Similarly, A100 (we used the 40 GB version) is capable of running batch sizes of 64, but the other GPUs could only reach 32 in our tests.
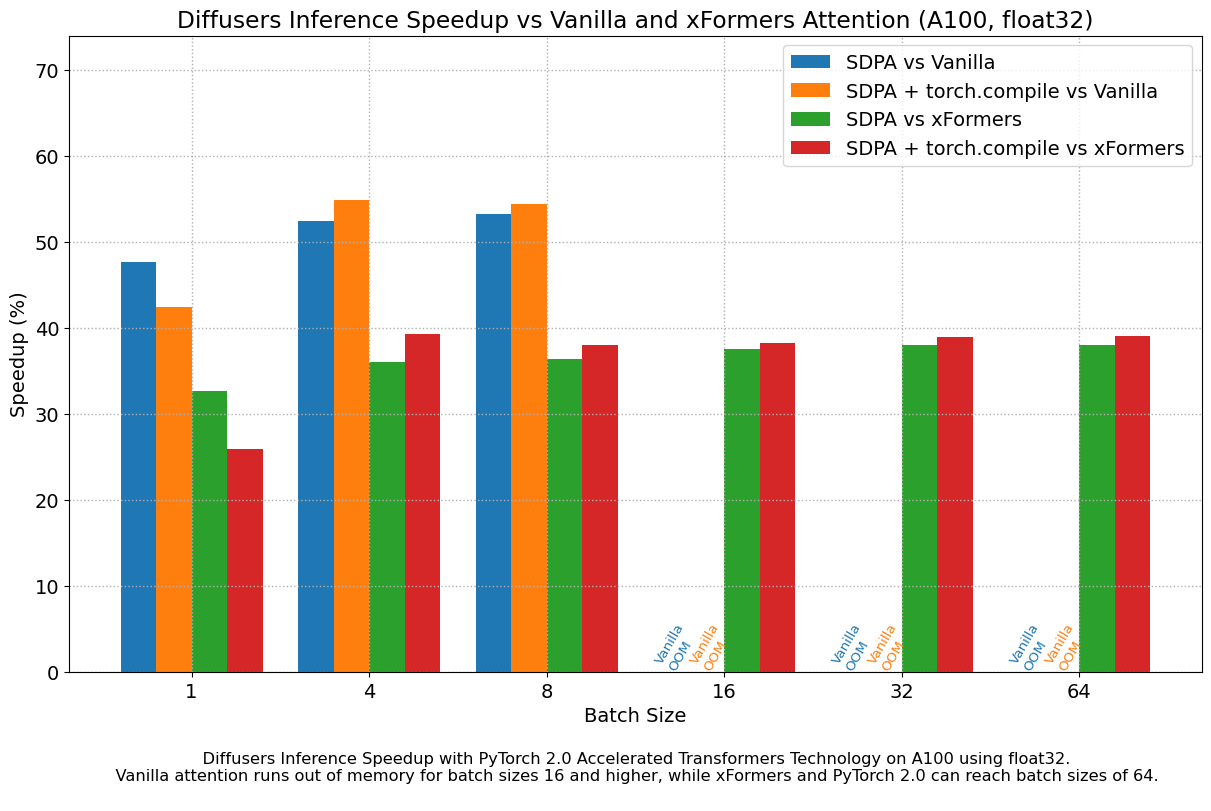
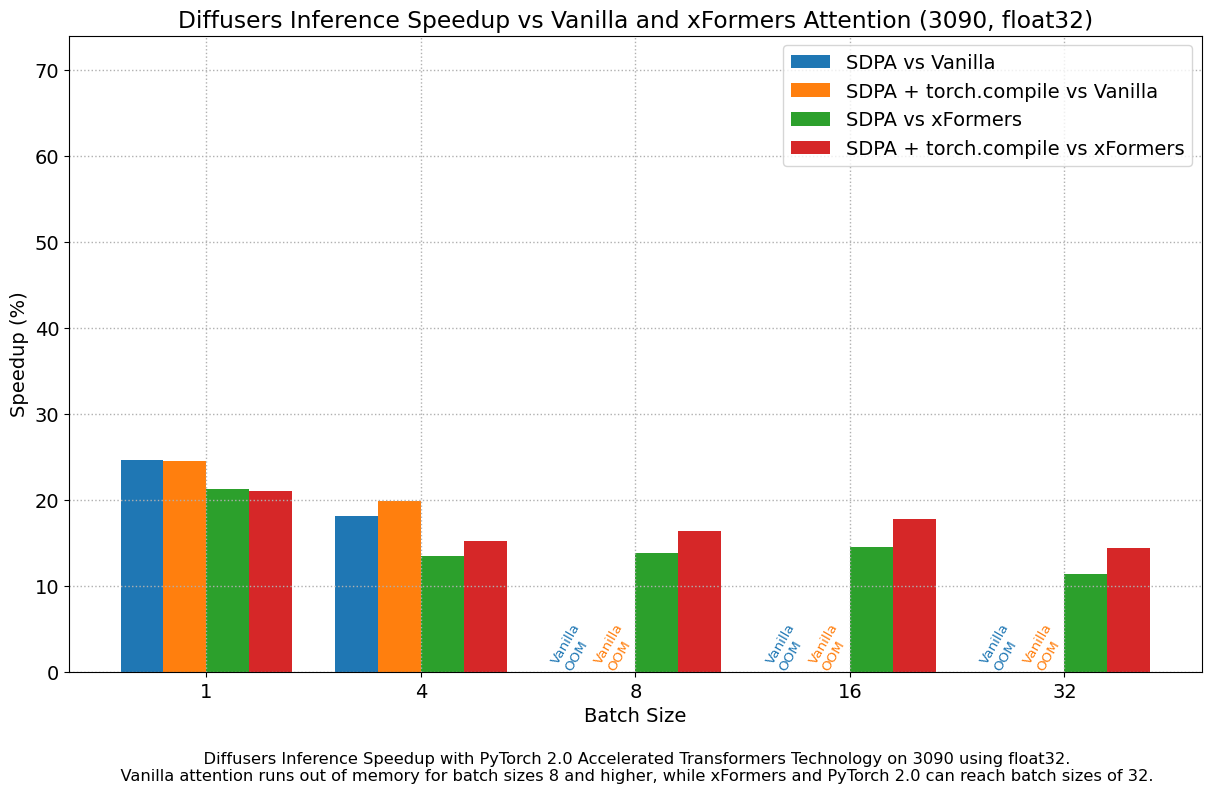
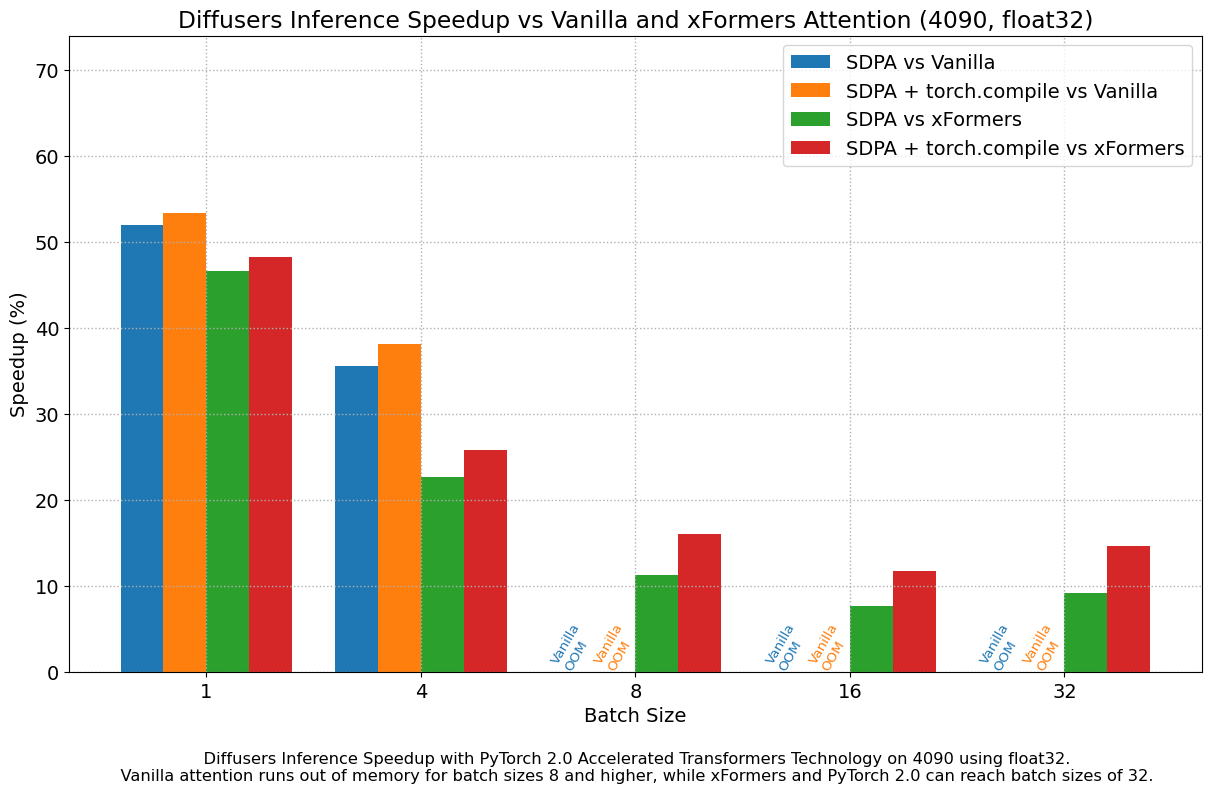
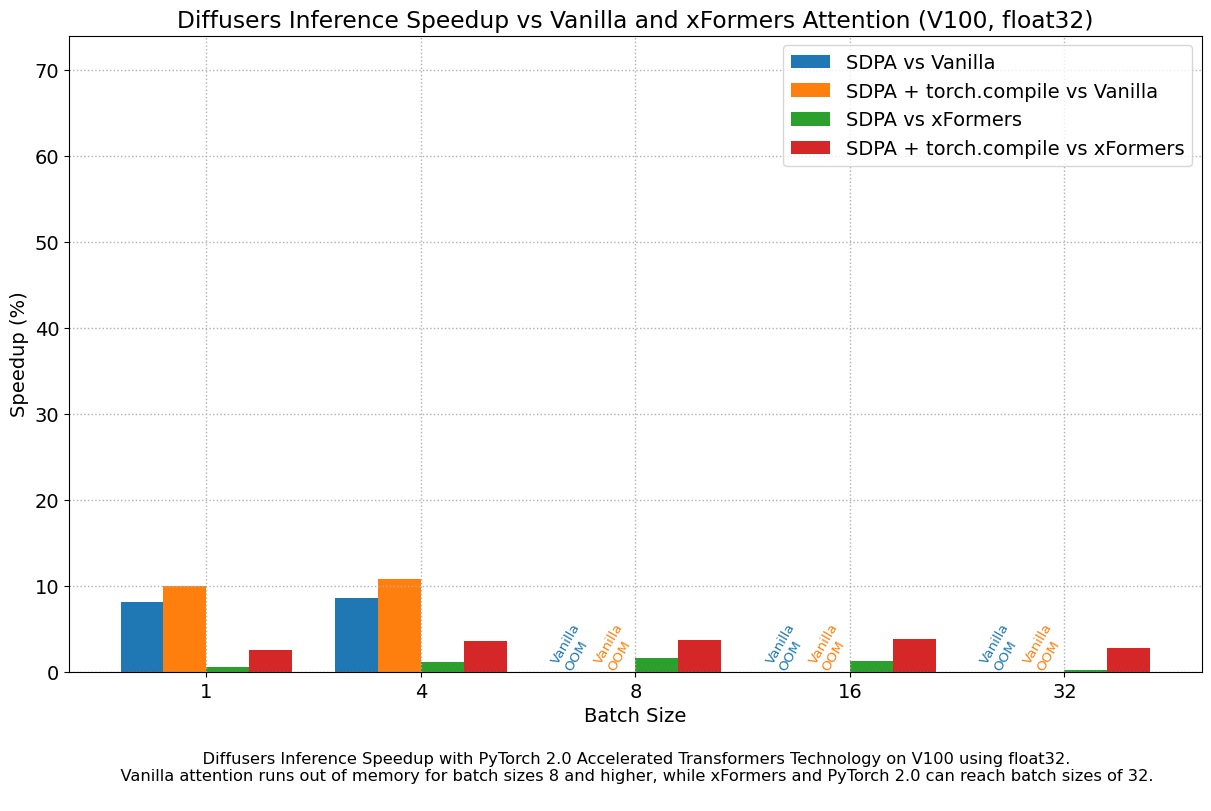
We found very significant performance improvements over vanilla attention across the board, without even using torch.compile(). An out of the box installation of PyTorch 2.0 and diffusers yields about 50% speedup on A100 and between 35% and 50% on 4090 GPUs, depending on batch size. Performance improvements are more pronounced for modern CUDA architectures such as Ada (4090) or Ampere (A100), but they are still very significant for older architectures still heavily in use in cloud services.
In addition to faster speeds, the accelerated transformers implementation in PyTorch 2.0 allows much larger batch sizes to be used. A single 40GB A100 GPU runs out of memory with a batch size of 10, and 24 GB high-end consumer cards such as 3090 and 4090 cannot generate 8 images at once. Using PyTorch 2.0 and diffusers we could achieve batch sizes of 48 for 3090 and 4090, and 64 for A100. This is of great significance for cloud services and applications, as they can efficiently process more images at a time.
When compared with PyTorch 1.13.1 + xFormers, the new accelerated transformers implementation is still faster and requires no additional packages or dependencies. In this case we found moderate speedups of up to 2% on datacenter cards such as A100 or T4, but performance was great on the two last generations of consumer cards: up to 20% speed improvement on 3090 and between 10% and 45% on 4090, depending on batch size.
When torch.compile() is used, we get an additional performance boost of (typically) 2% and 3% over the previous improvements. As compilation takes some time, this is better geared towards user-facing inference services or training. Update: improvements achieved by torch.compile() are much larger when graph breaks are minimized, see the new section for details.
Results in float16
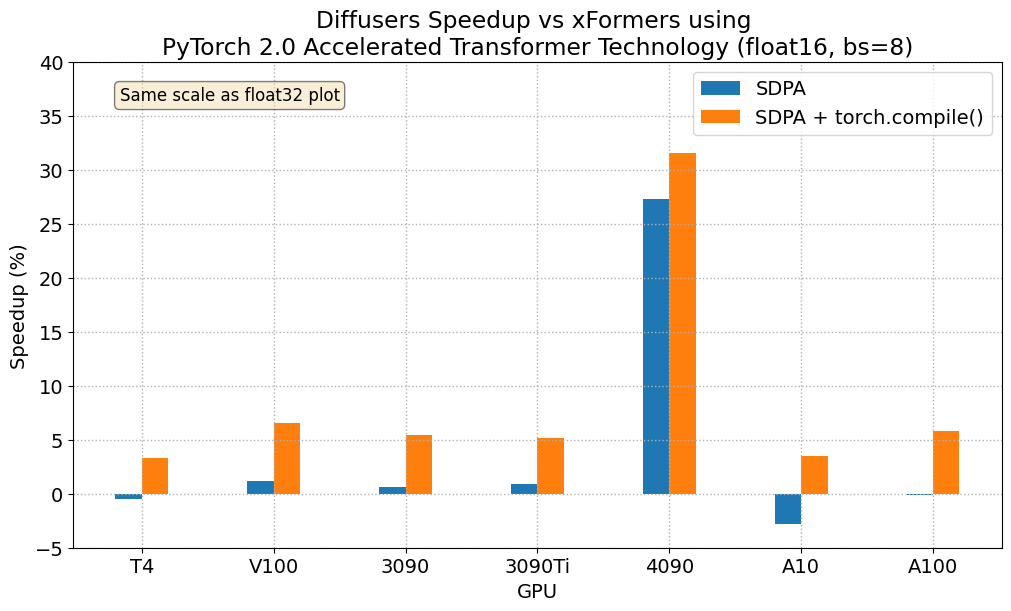
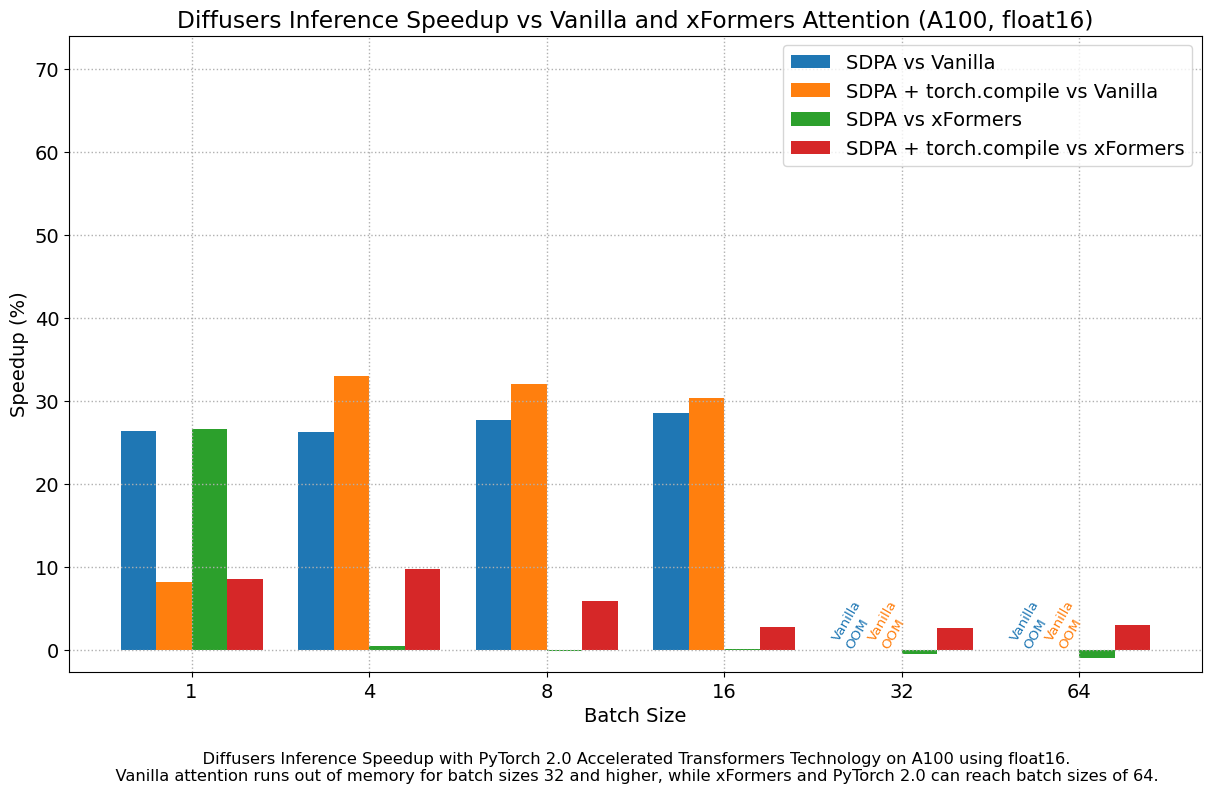
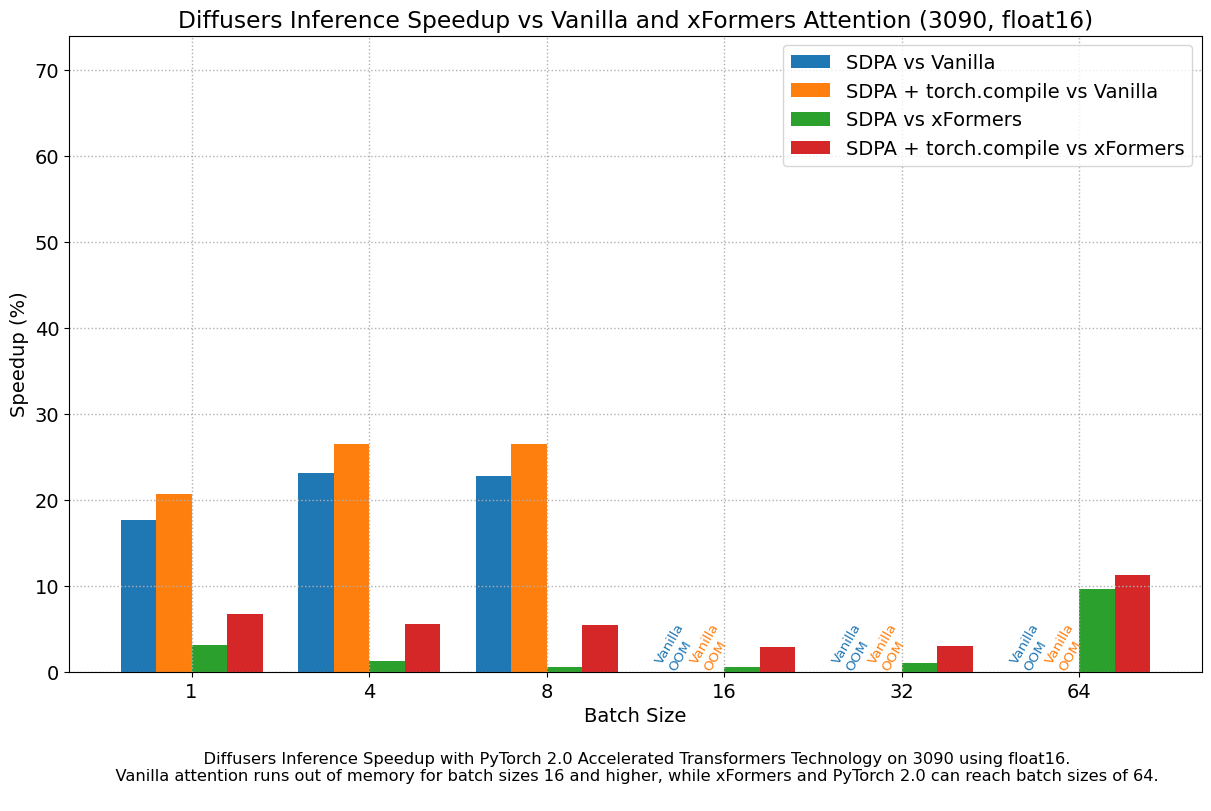
When we consider float16 inference, the performance improvements of the accelerated transformers implementation in PyTorch 2.0 are between 20% and 28% over standard attention, across all the GPUs we tested, except for the 4090, which belongs to the more modern Ada architecture. This GPU benefits from a dramatic performance improvement when using PyTorch 2.0 nightlies. With respect to optimized SDPA vs xFormers, results are usually on par for most GPUs, except again for the 4090. Adding torch.compile() to the mix boosts performance a few more percentage points across the board.
Performance of torch.compile() after minimizing graph breaks
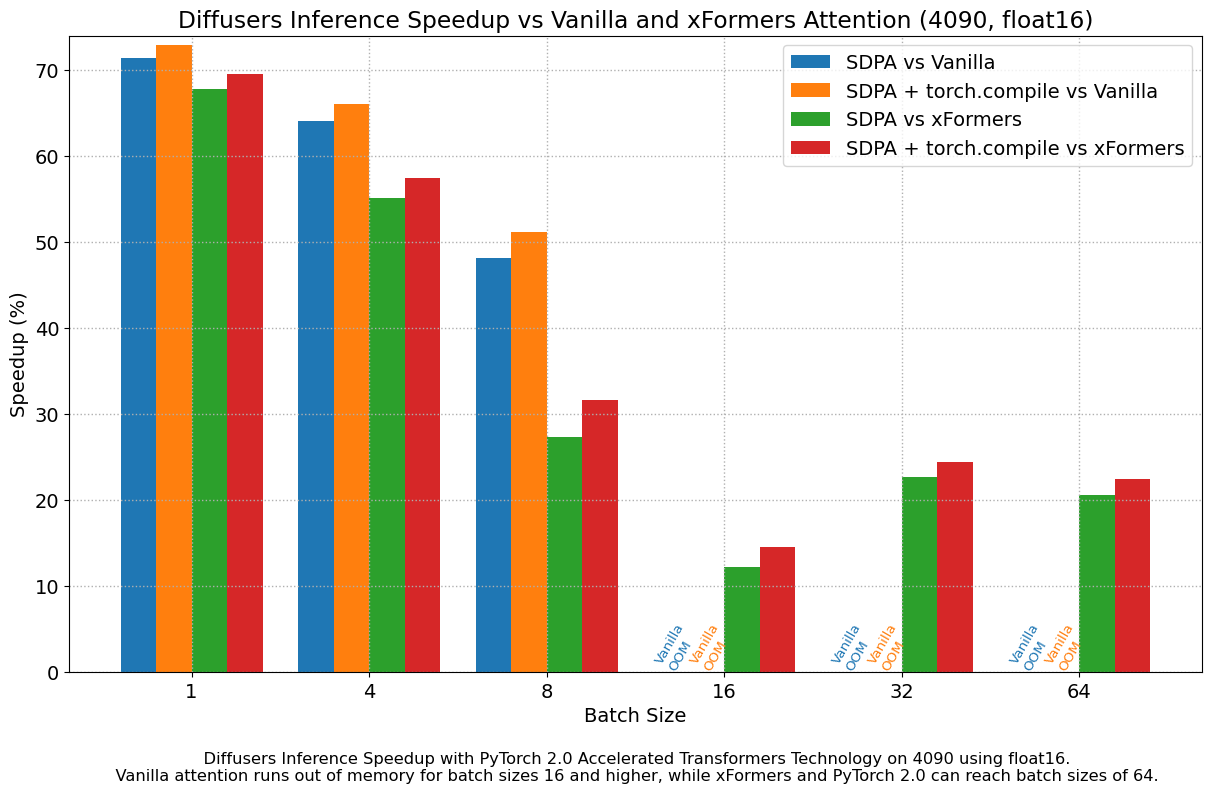
In the previous sections we saw that using the accelerated transformers implementation of PyTorch 2.0 provides important performance improvements with respect to earlier versions of PyTorch (with or without xFormers). However, torch.compile() only contributed modest marginal improvements. With the help of the PyTorch team we discovered that the reason for those moderate improvements was that some operations in the diffusers source code were causing graph breaks, which prevented torch.compile() from taking full advantage of graph optimizations.
After fixing the graph breaks (see these PRs for details), we measured the additional improvement of torch.compile() vs the uncompiled version of PyTorch 2, and we saw very important incremental performance gains. The following chart was obtained using a nightly version of PyTorch 2 downloaded on May 1st, 2023, and it shows improvements in the range of ~13% to 22% for most workloads. The performance gains get better for modern GPU families, achieving more than 30% for A100. There are also two outliers in the chart. First, we see a performance decrease on T4 for a batch size of 16, which imposes a huge memory pressure on that card. At the opposite end of the spectrum, we see a performance increase on A100 of more than 100% when using a batch size of only 1, which is interesting but not representative of real-world use of a gpu with such large amount of RAM – larger batch sizes capable of serving multiple customers will usually be more interesting for service deployment on A100.
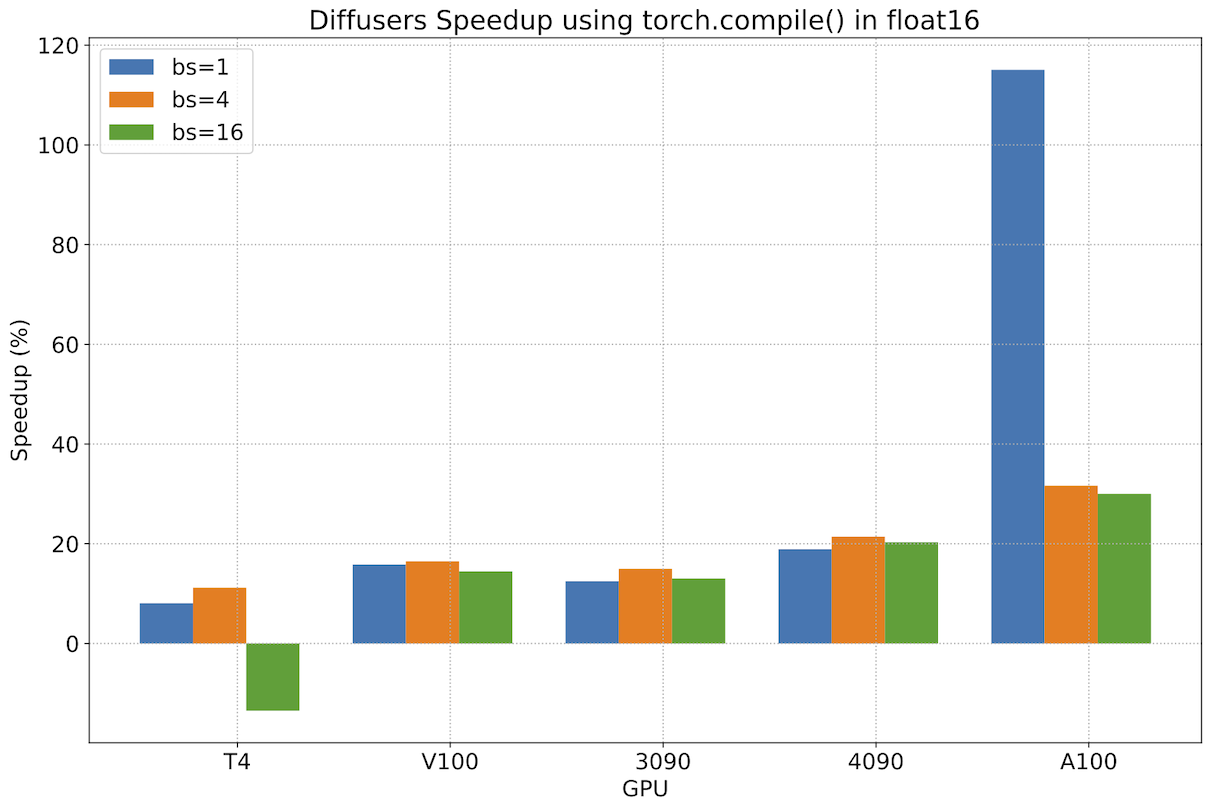
To stress it again, these performance gains are additional to the ones achieved by migrating to PyTorch 2 and using the accelerated transformers scaled dot-product attention implementation. We recommend using torch.compile() when deploying diffusers in production.
Conclusions
PyTorch 2.0 comes with multiple features to optimize the crucial components of the foundational transformer block, and they can be further improved with the use of torch.compile. These optimizations lead to significant memory and time improvements for diffusion models, and remove the need for third-party library installations.
To take advantage of these speed and memory improvements all you have to do is upgrade to PyTorch 2.0 and use diffusers >= 0.13.0.
For more examples and in-detail benchmark numbers, please also have a look at the Diffusers with PyTorch 2.0 docs.
Acknowledgement
The authors are grateful to the PyTorch team for creating such excellent software.
