Story at a Glance
- Although the PyTorch* Inductor C++/OpenMP* backend has enabled users to take advantage of modern CPU architectures and parallel processing, it has lacked optimizations, resulting in the backend performing worse than eager mode in terms of end-to-end performance.
- Intel optimized the Inductor backend using a hybrid strategy that classified operations into two categories: Conv/GEMM and non-Conv/GEMM element-wise and reduction ops.
- For popular deep learning models, this hybrid strategy demonstrates promising performance improvements compared to eager mode and improves the C++/OpenMP backend’s efficiency and reliability for PyTorch models.
Inductor Backend Challenges
The PyTorch Inductor C++/OpenMP backend enables users to take advantage of modern CPU architectures and parallel processing to accelerate computations.
However, during the early stages of its development, the backend lacked some optimizations, which prevented it from fully utilizing the CPU computation capabilities. As a result, for most models the C++/OpenMP backend performed worse than eager mode in terms of end-to-end performance, with 45% of TorchBench, 100% of Hugging Face, and 75% of TIMM models performing worse than eager mode.
In this post, we highlight Intel’s optimizations to the Inductor CPU backend, including the technologies and results.
We optimized the backend by using a hybrid strategy that classified operations into two categories: Conv/GEMM and non-Conv/GEMM element-wise and reduction ops. Post-op fusion and weight prepacking using the oneDNN performance library were utilized to optimize the former, while explicit vectorization in C++ codegen was used to optimize the latter.
This hybrid strategy demonstrated promising performance improvements compared to eager mode, particularly on popular deep learning models such as Inductor Hugging Face, Inductor TorchBench and Inductor TIMM. Overall, Intel’s optimizations improve the C++/OpenMP backend’s efficiency and reliability for PyTorch models.
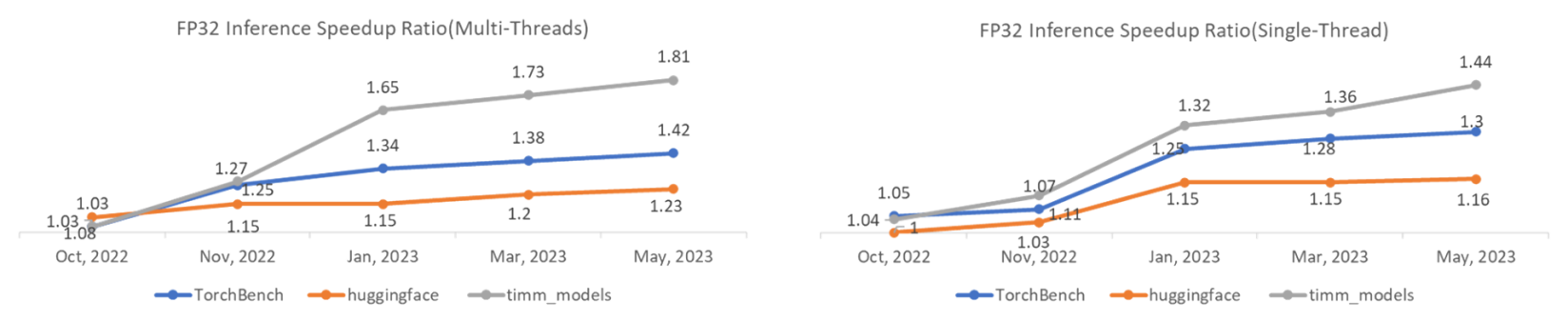
Figure 1: Performance Speedup Ratio Trend
Performance Status of Intel Hybrid Optimizations
Compared to eager mode with the hybrid optimizations, the C++/OpenMP backend shows promising performance improvements. We measured the performance of the three Inductor benchmark suites—TorchBench, Hugging Face, and TIMM—and the results are as follows. (Note: we publish our performance data twice per week on GitHub.)
Overall, these optimizations help to ensure that the C++/OpenMP backend provides efficient and reliable support for PyTorch models.
Passrate
+----------+------------+-------------+-------------+
| Compiler | torchbench | huggingface | timm_models |
+----------+------------+-------------+-------------+
| inductor | 93%, 56/60 | 96%, 44/46 | 100%, 61/61 |
+----------+------------+-------------+-------------+
Geometric mean speedup (Single-Socket Multi-threads)
+----------+------------+-------------+-------------+
| Compiler | torchbench | huggingface | timm_models |
+----------+------------+-------------+-------------+
| inductor | 1.39x | 1.20x | 1.73x |
+----------+------------+-------------+-------------+
Individual Model Performance
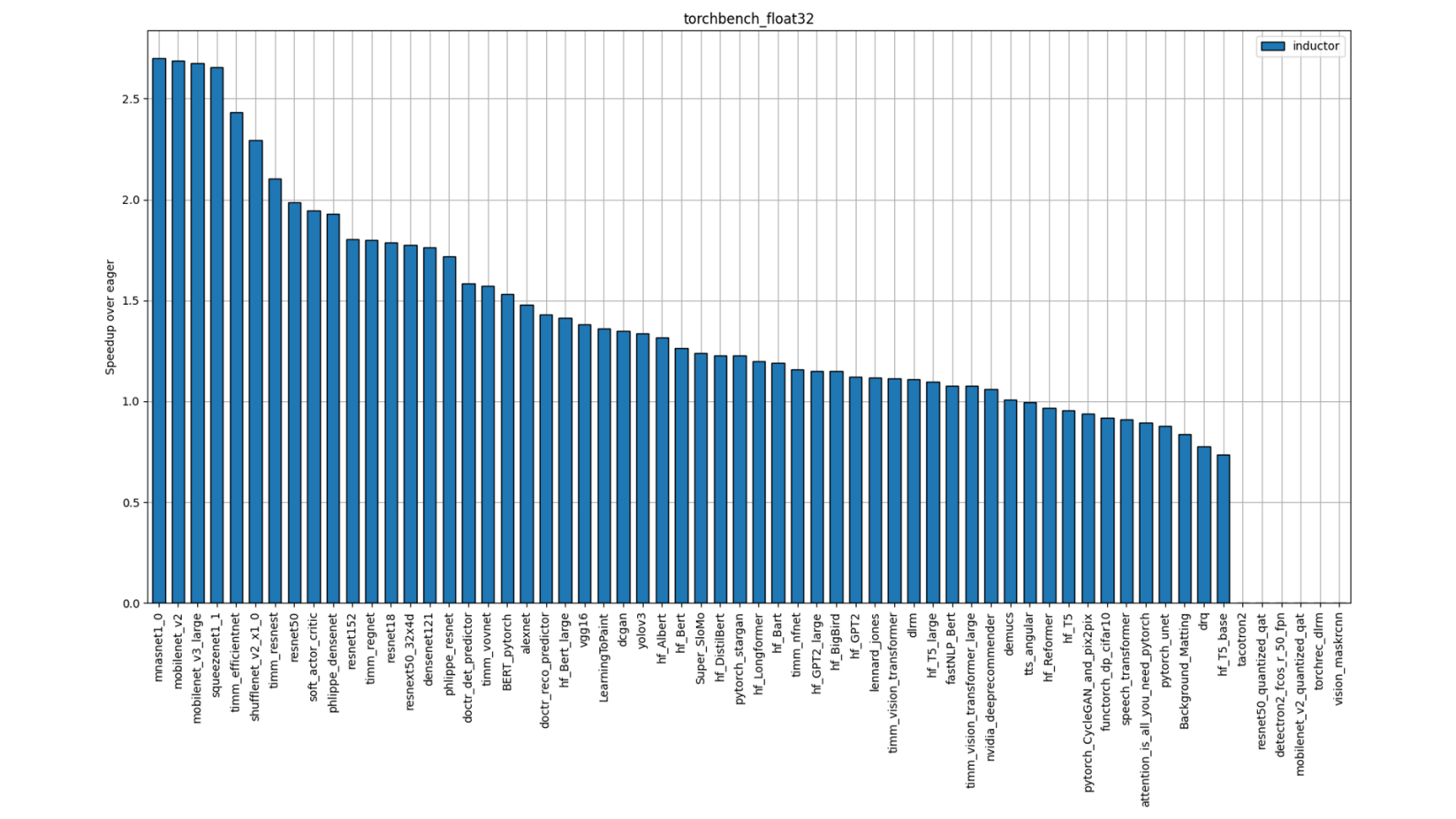
Figure 2: TorchBench FP32 Performance (Single-Socket Multi-threads)
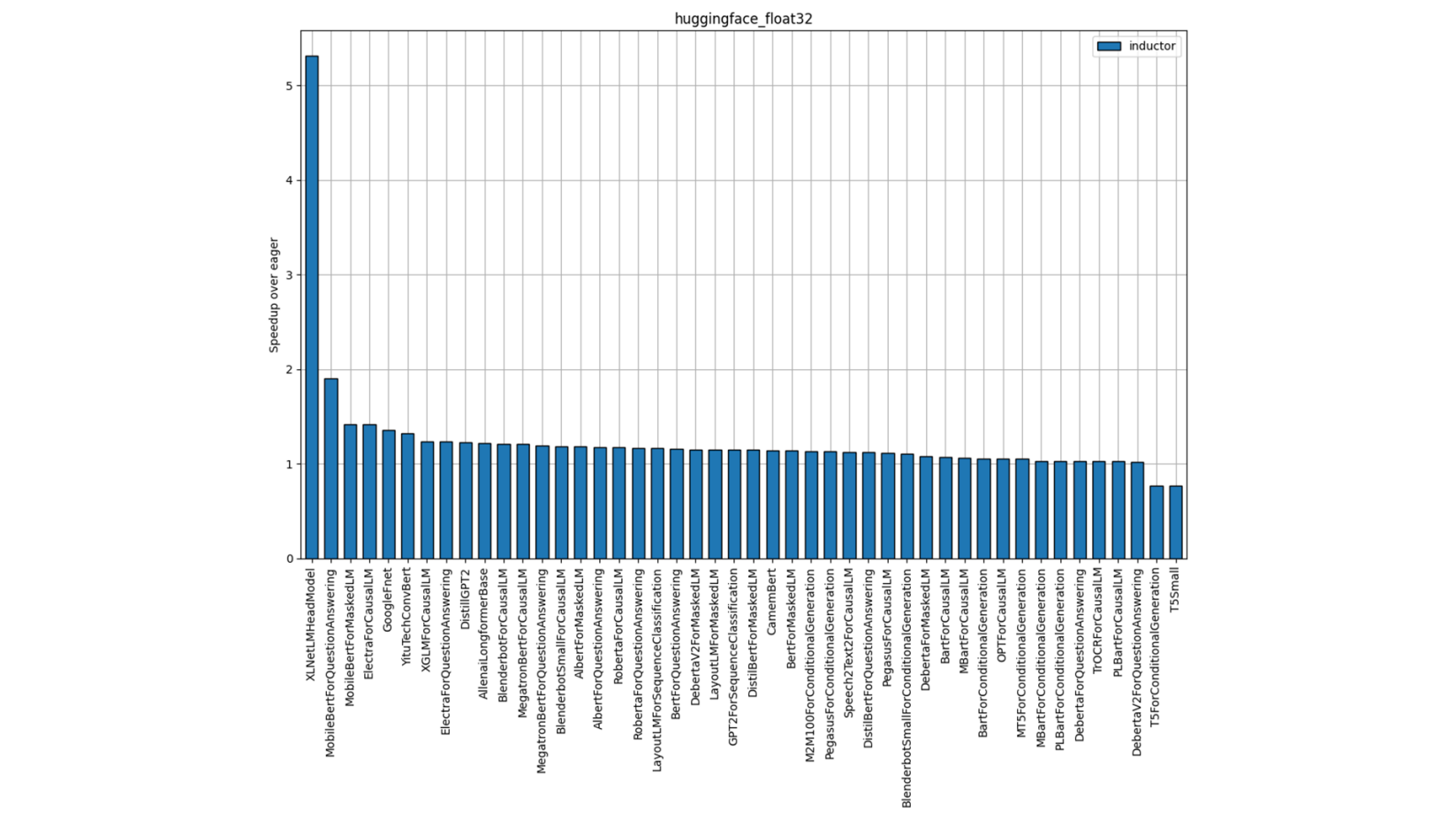
Figure 3: Hugging Face FP32 Performance (Single-Socket Multi-thread)
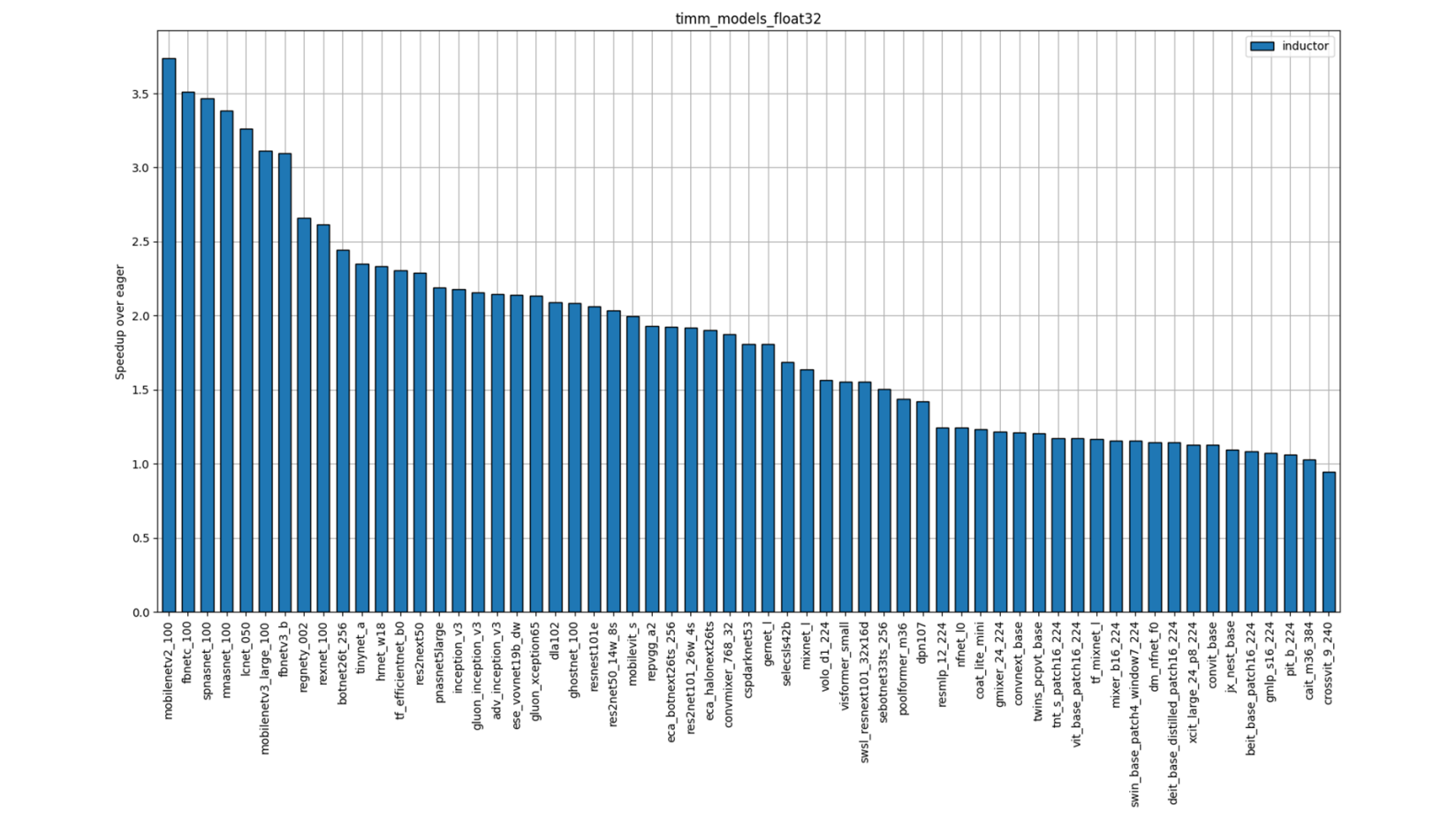
Figure 4: TIMM FP32 Performance (Single-Socket Multi-threads)
Geometric mean speedup (Single-core Single-thread)
+----------+------------+-------------+-------------+
| Compiler | torchbench | huggingface | timm_models |
+----------+------------+-------------+-------------+
| inductor | 1.29x | 1.15x | 1.37x |
+----------+------------+-------------+-------------+
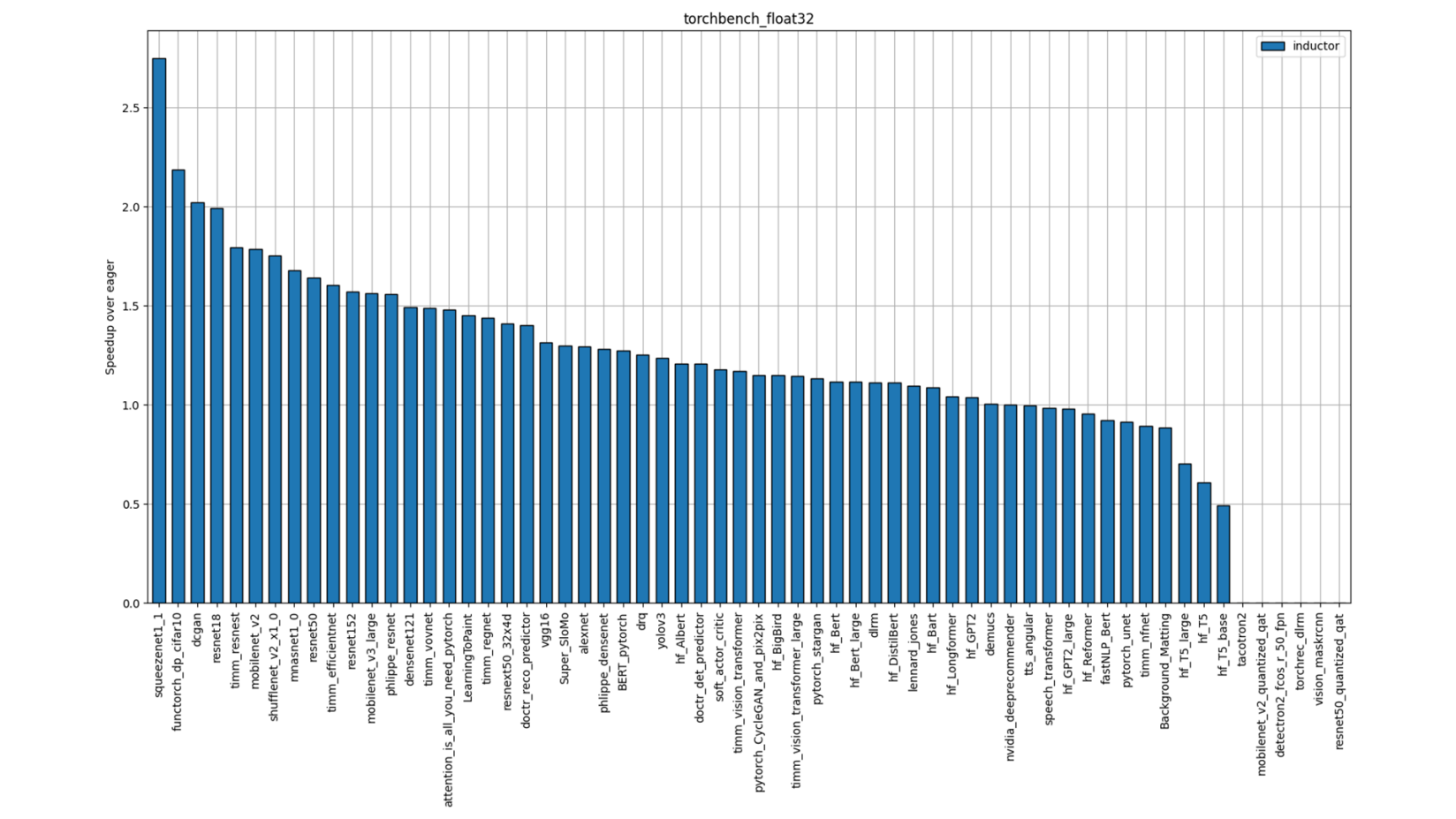
Figure 5: TorchBench FP32 Performance (Single-Socket Single-thread)
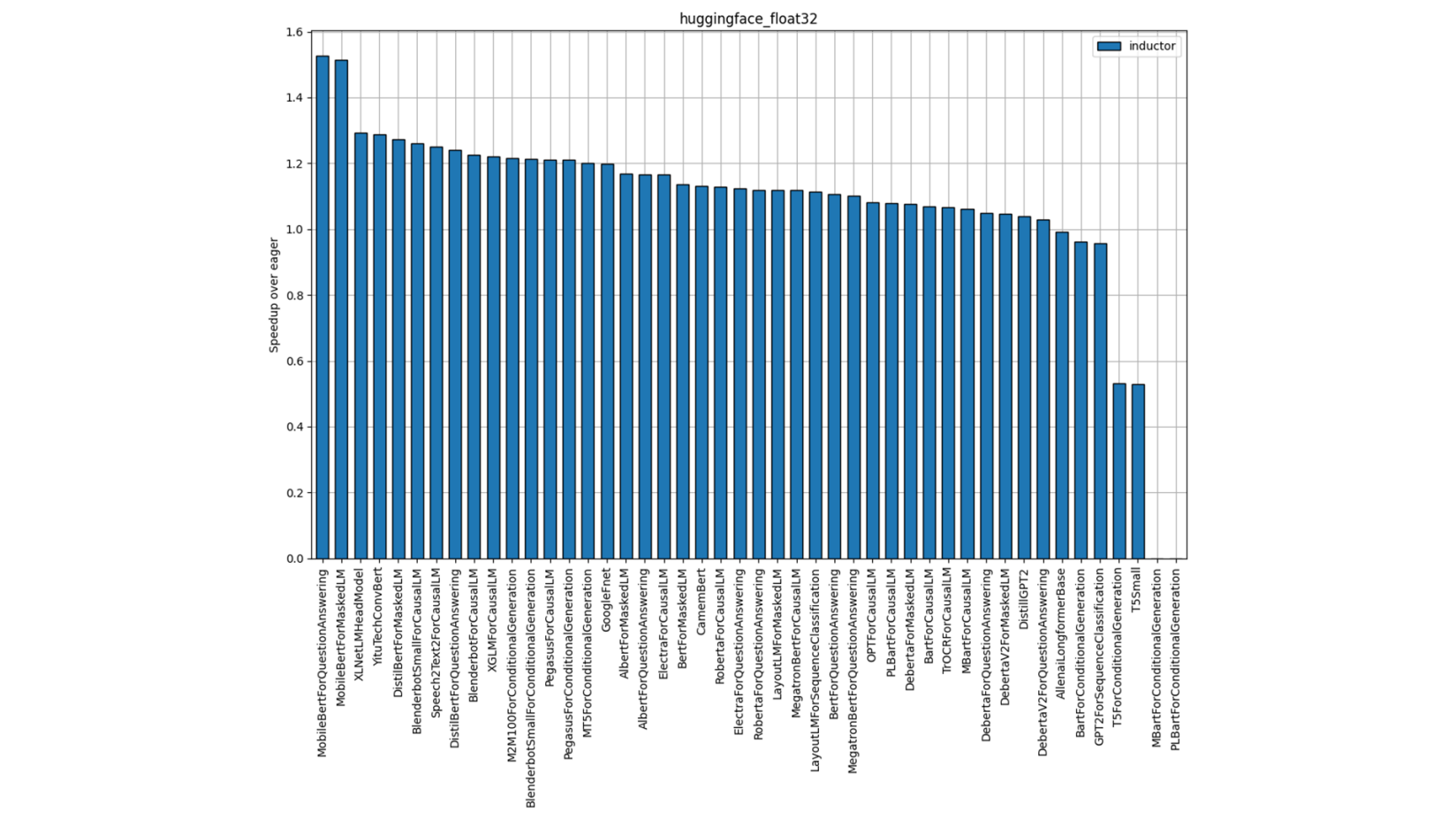
Figure 6: Hugging Face FP32 Performance (Single-Socket Single Thread)
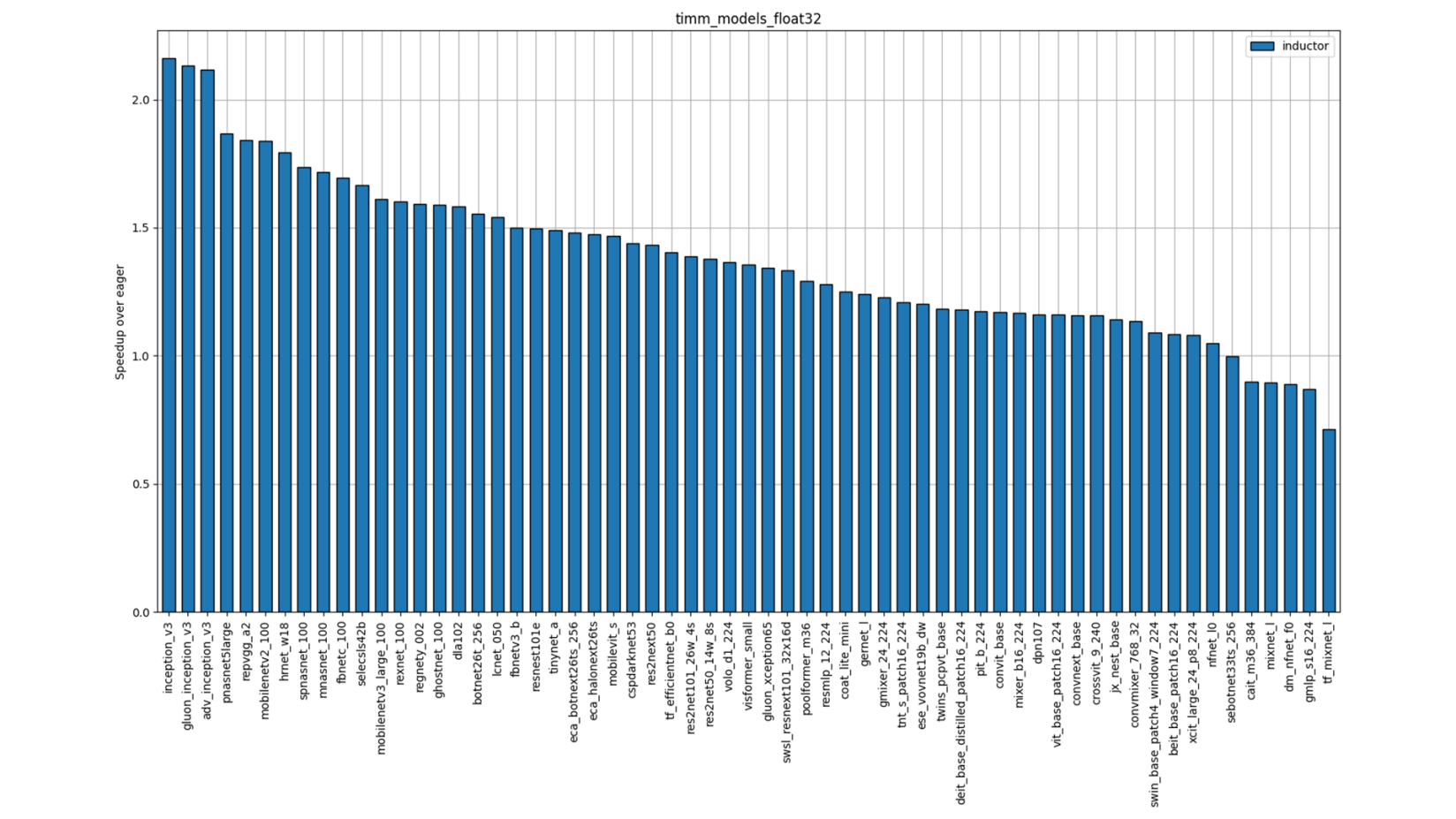
Figure 7: TIMM FP32 Performance (Single-Socket Single-thread)
Technical Deep Dive
Now, let’s take a closer look at the two primary optimizations used in the Inductor C++/OpenMP backend:
- weight prepacking and post-operation fusion via oneDNN library
- explicit vectorization in Inductor C++ codegen
Weight Prepackaging & Post-op Fusion via oneDNN
Shorthand for Intel® oneAPI Deep Neural Network Library, oneDNN library provides a range of post-op fusions (i.e., fuse convolution and matmal with its consecutive operation) that can benefit popular models. The Intel® Extension for PyTorch has implemented most of these fusions and has achieved significant performance improvements. As a result, we have upstreamed all of these fusions that have been applied in Intel’s PyTorch extension to Inductor, enabling a wider range of models to benefit from these optimizations. We have defined these fusions as operators under the mkldnn namespace. This allows the Python module to invoke these mkldnn operations directly.
Currently, the defined fused operations are as follows. You can find these defined fused operations at RegisterMkldnnOpContextClass.cpp.
_linear_pointwise: Fuses Linear and its post-unary element-wise operations_linear_pointwise.binary: Fuses Linear and its post-binary element-wise operations_convolution_pointwise: Fuses Convolution and its post-unary element-wise operations_convolution_pointwise.binary: Fuses Convolution and its post-binary element-wise operations
The detailed fusion patterns are defined in the mkldnn.py file: convolution/linear + sigmoid/hardsigmoid/tanh/hardtanh/hardswish/leaky_relu/gelu/relu/relu6/siluconvolution/linear + add/add_/iadd/sub/sub_
On the Inductor side, we apply these fusions on the FX graph that has been lowered. We have defined mkldnn_fuse_fx as the entry point to apply all the fusions. The code snippet for this is as follows:
def mkldnn_fuse_fx(gm: torch.fx.GraphModule, example_inputs):
...
gm = fuse_unary(gm)
gm = fuse_binary(gm)
...
if config.cpp.weight_prepack:
gm = pack_module(gm)
return gm
In the mkldnn_fuse_fx function, we apply fusion on the FX graph that hasn’t been lowered yet. To fuse convolution/linear and its consecutive elementwise operations, we invoke fuse_unary and fuse_binary as follows:
gm = fuse_unary(gm)
gm = fuse_binary(gm)
In addition to the post-op fusion, we apply weight prepacking to improve the Conv/GEMM performance further:
gm = pack_module(gm)
Weight prepacking involves rearranging the weight tensor in a blocked layout, which:
- can improve vectorization and cache reuse compared to plain formats like NCHW or NHWC and;
- can help avoid weight reordering at runtime, which can reduce overhead and improve performance and;
- increases memory usage as the tradeoff.
For these reasons, we provide config.cpp.weight_prepack flag in Inductor to provide users with more control over this optimization, allowing them to enable it based on their specific needs.
Explicit Vectorization in Inductor C++ Codegen
Vectorization is a key optimization technique that can significantly improve the performance of numerical computations. By utilizing SIMD (Single Instruction, Multiple Data) instructions, vectorization enables multiple computations to be performed simultaneously on a single processor core, which can lead to significant performance improvements.
In the Inductor C++/OpenMP backend, we use Intel® AVX2 and Intel® AVX-512 ISA (Instruction Set Architecture) options for vectorization by leveraging the aten vectorization library to facilitate the implementation. Aten vectorization supports multiple platforms, including x86 and Arm, as well as multiple data types. It can be extended to support other ISAs easily by adding more VecISA sub-classes. This allows Inductor to easily support other platforms and data types in the future.
Due to differences in platforms, the C++/OpenMP backend of Inductor starts by detecting the CPU features to determine the vectorization bit width at the beginning of code generation. By default, if the machine supports both AVX-512 and AVX2, the backend will choose 512-bit vectorization.
If the hardware supports vectorization, the C++/OpenMP backend first detects if the loop body can be vectorized or not. There are primarily three scenarios that we are not able to generate kernel with vectorization:
- Loop body lacks vector intrinsics support, e.g.,
randandatomic_add. - Loop body lacks efficient vector intrinsics support, e.g., non-contiguous
load/store. - Data types with vectorization not yet supported but work in progress, e.g., integer, double, half, and bfloat16.
To address this issue, the C++/OpenMP backend uses CppVecKernelChecker to detect whether all operations in a particular loop body can be vectorized or not. In general, we classified the operations into two categories by identifying if they depend on the context.
For most elementwise operations such as add, sub, relu, vectorization is straightforward, and their execution does not depend on context.
However, for certain other operations, their semantics are more complex and their execution depends on context through static analysis.
For example, let’s consider the where operation that takes in mask, true_value, and false_value while the mask value is loaded from a uint8 tensor. The fx graph could be as follows:
graph():
%ops : [#users=9] = placeholder[target=ops]
%get_index : [#users=1] = call_module[target=get_index](args = (index0,), kwargs = {})
%load : [#users=1] = call_method[target=load](args = (%ops, arg1_1, %get_index), kwargs = {})
%to_dtype : [#users=1] = call_method[target=to_dtype](args = (%ops, %load, torch.bool), kwargs = {})
...
%where : [#users=1] = call_method[target=where](args = (%ops, %to_dtype, %to_dtype_2, %to_dtype_3), kwargs = {})
Regarding uint8, it is a general data type and could be used for computation but is not limited to being used as Boolean for mask. Hence, we need to analyze its context statically. In particular, the CppVecKernelChecker will check whether a uint8 tensor is only used by to_dtype and to_dtype is only used by where. If yes, it could be vectorized. Otherwise, it will fall back to the scalar version. The generated code could be as follows:
Scalar Version
auto tmp0 = in_ptr0[i1 + (17*i0)];
auto tmp3 = in_ptr1[i1 + (17*i0)];
auto tmp1 = static_cast<bool>(tmp0);
auto tmp2 = static_cast<float>(-33.0);
auto tmp4 = tmp1 ? tmp2 : tmp3;
tmp5 = std::max(tmp5, tmp4);
Vectorization Version
float g_tmp_buffer_in_ptr0[16] = {0};
// Convert the flag to float for vectorization.
flag_to_float(in_ptr0 + (16*i1) + (17*i0), g_tmp_buffer_in_ptr0, 16);
auto tmp0 = at::vec::Vectorized<float>::loadu(g_tmp_buffer_in_ptr0);
auto tmp3 = at::vec::Vectorized<float>::loadu(in_ptr1 + (16*i1) + (17*i0));
auto tmp1 = (tmp0);
auto tmp2 = at::vec::Vectorized<float>(static_cast<float>(-33.0));
auto tmp4 = decltype(tmp2)::blendv(tmp3, tmp2, tmp1);
In addition to context analysis, the C++/OpenMP backend also incorporates several other vectorization-related optimizations. These include:
- Tiled kernel implementation for supporting transpose load - cpp.py
- Data type demotion based on value range - cpp.py
- Replacement of sleef implementation with oneDNN/oneMKL implementation for optimizing aten vectorization - #94577, #92289, #91613
In summary, we examined vectorization optimization in Inductor C++ backend for FP32 training and inference of 150 benchmark models with 90% of inference kernels and 71% of training kernels being vectorized.
In terms of inference, a total of 28,185 CPP kernels were generated, with 25,579 (90%) of them being vectorized, while the remaining 10% were scalar. As for training, 103,084 kernels were generated, with 73,909 (71%) being vectorized and 29% not vectorized.
The results indicate that the vectorization of inference kernels is quite impressive (there is still some work to be done in training kernels since we just started to work on the training). The remaining non-vectorized kernels are analyzed in different categories, highlighting the next steps to improve vectorization coverage: index-related operations, int64 support, vertical reduction, vectorization with fallback, and more.
In addition, we also optimized the C++/OpenMP backend with other optimizations like buffer-reuse and CppWrapper.
Future Work
The next step, we will continue optimizing the C++/OpenMP backend and extend it to support more data types as the next step. This includes:
- Improve vectorization coverage
- Support and optimize low precision kernel including BF16, FP16, Quantization
- Training optimization
- Loop tiling
- Autotune
- Further fusion optimization of Conv/GEMM kernels.
- Explore alternative codegen paths: clang/llvm/triton
Summary
Inductor C++/OpenMP backend is a flexible and efficient backend for the CPU. This blog describes the optimizations used in the C++/OpenMP backend of Inductor for inference and training of three benchmark suites – TorchBench, Hugging
Face and TIMM. The primary optimizations include weight prepacking and post-operation fusion via the oneDNN library, as well as explicit vectorization in Inductor C++ codegen using AVX2 and AVX-512 instructions.
The results show that 90% of inference kernels and 71% of training kernels are vectorized, indicating impressive vectorization for inference and room for improvement in training. In addition, we also applied other optimizations like buffer-reuse and CppWrapper. And we will continuously focus on the future work mentioned above to further improve the performance.
Acknowledgements
The results presented in this blog post are the culmination of a collaborative effort between the Intel PyTorch team and Meta. We would like to express our sincere gratitude to @jansel, @desertfire, and @Chillee for their invaluable contributions and unwavering support throughout the development process. Their expertise and dedication have been instrumental in achieving the optimizations and performance improvements discussed here.
Configuration Details
Hardware Details
| Item | Value |
| Manufacturer | Amazon EC2 |
| Product Name | c6i.16xlarge |
| CPU Model | Intel(R) Xeon(R) Platinum 8375C CPU @ 2.90GHz |
| Installed Memory | 128GB (1x128GB DDR4 3200 MT/s [Unknown]) |
| OS | Ubuntu 22.04.2 LTS |
| Kernel | 5.19.0-1022-aws |
| Microcode | 0xd000389 |
| GCC | gcc (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0 |
| GLIBC | ldd (Ubuntu GLIBC 2.35-0ubuntu3.1) 2.35 |
| Binutils | GNU ld (GNU Binutils for Ubuntu) 2.38 |
| Python | Python 3.10.6 |
| OpenSSL | OpenSSL 3.0.2 15 Mar 2022 (Library: OpenSSL 3.0.2 15 Mar 2022) |
Software Details
| SW | Nightly commit | Main commit |
| Pytorch | a977a12 | 0b1b063 |
| Torchbench | / | a0848e19 |
| torchaudio | 0a652f5 | d5b2996 |
| torchtext | c4ad5dd | 79100a6 |
| torchvision | f2009ab | b78d98b |
| torchdata | 5cb3e6d | f2bfd3d |
| dynamo_benchmarks | fea73cb | / |
Configuration
- Intel OpenMP
- Jemalloc - oversize_threshold:1,background_thread:true,metadata_thp:auto,dirty_decay_ms:-1,muzzy_decay_ms:-1
- Single-Socket Multi-threads: #of Instances: 1; Cores/Instance: 32
- Single-Core Single-thread: #of Instances: 1; Cores/Instance: 1
